Alta disponibilidad de ThingWorx
Resumen de la agrupación de alta disponibilidad de ThingWorx
Para reducir la duración de las interrupciones de los sistemas importantes de Internet de las cosas (IoT), se puede configurar ThingWorx para que funcione en un entorno de alta disponibilidad en modo de clúster. La agrupación proporciona escalabilidad adicional y alta disponibilidad, suponiendo que todos los componentes estén configurados correctamente.
|
|
La agrupación de alta disponibilidad no se debe utilizar para una solución de recuperación ante desastres.
|
|
|
No se soporta el uso de múltiples zonas de disponibilidad para una implementación de alta disponibilidad. La latencia de la red entre las zonas puede resultar demasiado elevada para la comunicación constante entre los nodos de ThingWorx y Apache Ignite.
|
En las siguientes secciones se describen la instalación y configuración de un entorno de agrupación, así como los componentes y las consideraciones para una implementación de alta disponibilidad de ThingWorx HA.
Todas las implementaciones de alta disponibilidad requieren recursos adicionales en comparación con una implementación diseñada solo para cumplir con los requisitos funcionales y de escala. Estos recursos adicionales se basan en el hardware (como servidores, discos, equilibradores de la carga, etc.) y en el software (como los servicios de sincronización y los equilibradores de la carga). Los recursos adicionales se configuran para garantizar que no haya puntos únicos de fallo en la implementación de alta disponibilidad.
Todas las implementaciones de alta disponibilidad deben basarse en un SLA (contrato de nivel de servicio) en el que se hayan analizado los requisitos de tiempo de actividad de la aplicación para la implementación. Por ejemplo, ¿cuántas horas por mes puede estar fuera de línea el sistema? ¿Está permitido el tiempo de inactividad para fallos del sistema, para las actualizaciones de la aplicación o para ambos? El número de recursos adicionales necesarios para un sistema de alta disponibilidad depende de lo que se ha diseñado que el SLA consiga. En general, a medida que el SLA crece, también lo hace la necesidad de recursos para satisfacerlo.
Glosario de términos
• alta disponibilidad
Sistema o componente que está continuamente operativo durante un período prolongado de tiempo.
• escalabilidad
La capacidad de aumentar la carga que un sistema puede soportar al aumentar la memoria, el disco o la CPU, o al añadir servidores.
• clúster
Instancias de la misma aplicación que pueden funcionar simultáneamente. Un clúster proporciona alta disponibilidad y escalabilidad.
• singleton
El servidor singleton es un servidor en el clúster que gestionará los comportamientos entre clústeres, tales como los temporizadores y los programadores. Permite garantizar que las tareas se ejecutan una sola vez en el clúster.
• dirección IP virtual
Dirección IP que representa una aplicación. Los clientes que utilizan la dirección IP virtual se suelen enrutar a un equilibrador de la carga que, a continuación, dirige la solicitud al servidor que ejecuta la aplicación.
• equilibrador de la carga
Un dispositivo que recibe el tráfico de red y lo distribuye a las aplicaciones listas para aceptarlo.
• conmutación por error
Modo de funcionamiento de copia de seguridad en el que componentes del sistema secundarios asumen las funciones de un componente del sistema (como un procesador, un servidor, una red o una base de datos) cuando el componente principal deja de estar disponible debido a un fallo o a un tiempo de inactividad programado.
• coherencia final
Los cambios tardan tiempo en propagarse a todos los servidores en un entorno de clúster. Para obtener más información, consulte Coherencia final.
• estado compartido
Estado que se comparte en varios servidores del clúster y se garantiza que será el mismo, independientemente del servidor que lo busque. Los datos de propiedad son un ejemplo de estado compartido, donde el valor de la propiedad actual es el mismo en todos los servidores.
Arquitectura de referencia de ThingWorx para alta disponibilidad
En la siguiente imagen se muestra ThingWorx en una configuración de clúster.
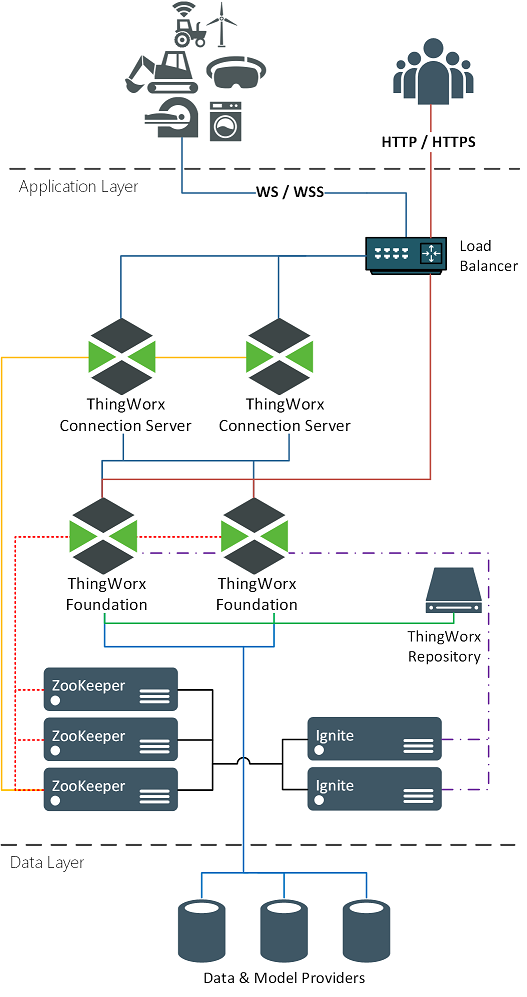
Los siguientes componentes pueden formar parte de una implementación de clúster:
• Usuarios y dispositivos: ningún rol en la funcionalidad de alta disponibilidad. Desde su perspectiva, no cambia nada. Siempre utilizan los mismos URL y direcciones IP, incluso si hay un cambio en el servidor ThingWorx principal.
• Barreras de seguridad: ninguna función de alta disponibilidad y se puede considerar opcional. A menudo, se colocan barreras de seguridad para implementar requisitos de seguridad.
• Equilibradores de la carga: los equilibradores de la carga gestionan una dirección IP virtual para la aplicación a la que soportan. Todo el tráfico ruteado a esa dirección IP virtual se dirige a la aplicación activa que puede recibirla.
• ThingWorx Connection Servers: recibe el tráfico de socket Web de los activos y lo rutea a ThingWorx Platform. Los servidores de conexión pueden funcionar en una configuración de clúster. Una vez que un activo se dirige a una instancia de Connection Server específica, siempre debe utilizar el mismo servidor de conexión. Si el servidor se queda fuera de línea, el activo debe redirigirse a otra instancia de Connection Server disponible.
• ThingWorx Foundation: recibe todo el tráfico de usuarios y activos.
• Almacenes de ThingWorx: ubicaciones de almacenamiento necesarias, tales como ThingworxPlatform, ThingworxStorage y ThingworxBackupStorage, y cualquier ubicación de almacenamiento adicional que se haya añadido para soportar la implementación. Para un entorno de clúster, las carpetas de almacenamiento deben existir en una ubicación de almacenamiento común a la que todos los servidores ThingWorx puedan acceder igualmente.
• Apache Zookeeper: Zookeeper es un servicio de coordinación centralizado que utilizan ThingWorx Connection Server e Ignite para la detección de servicios, la elección de singleton y la coordinación distribuida.
• Apache Ignite: Ignite proporciona una caché de memoria distribuida para compartir el estado en los servidores del clúster.
• PostgreSQL: en una configuración de alta disponibilidad, PostgreSQL funcionará a través de dos o más nodos de servidor en una configuración en espera activa. Un nodo recibe todo el tráfico de escritura y uno de los demás nodos puede recibir todo el tráfico de lectura. Se activa la replicación del flujo entre todos los nodos para mantener actualizado cada nodo.
• Pgpool-II: solo se utiliza en configuraciones de alta disponibilidad de PostgreSQL. Los nodos de Pgpool-II reciben las solicitudes de ThingWorx (lecturas y escrituras) y las dirigen al nodo de PostgreSQL adecuado. También supervisa la integridad de cada nodo PostgreSQL y puede iniciar tareas de conmutación por error y cambio de destino de tareas cuando uno de los nodos se queda fuera de línea.
• Microsoft SQL Server (no se encuentra en la imagen): se utiliza la conmutación por error de Microsoft para garantizar que al menos una instancia de MS SQL Server esté en línea y disponible.
• InfluxDB: no se requiere una implementación de InfluxDB para una configuración de agrupación de ThingWorx. Si se necesita para satisfacer los requisitos de ingesta de la implementación, asegúrese de que esté configurado para la alta disponibilidad.