ThingWorx Foundation デプロイメントのコンポーネント
ThingWorx のコンポーネントはクライアント、アプリケーション、データの 3 つのレイヤーにあると考えることができます。以下の図は ThingWorx ソリューションの基本的な出発点を示しています。
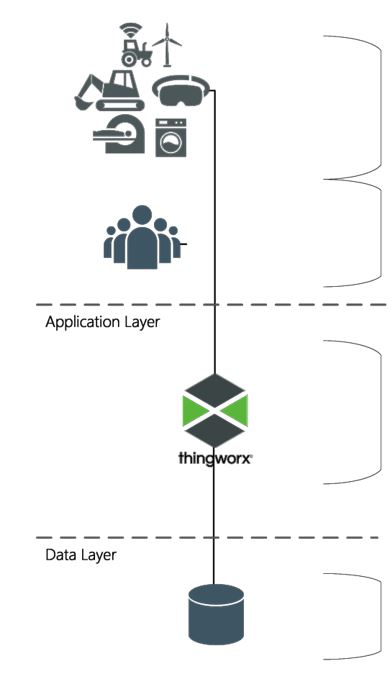 |
Thing/デバイス: このレイヤーには、ThingWorx プラットフォームと接続したり、ThingWorx プラットフォームにデータを送信したり、ThingWorx プラットフォームからコンテンツを受信したりする Thing、デバイス、エージェント、およびその他のアセットが含まれています。
ユーザー/クライアント: このレイヤーには、ThingWorx プラットフォームにアクセスするために使用する製品 (主に Web ブラウザ) が含まれています。
|
|
プラットフォーム: プラットフォームレイヤー (アプリケーション層) には、ThingWorx システムのハブとして機能する ThingWorx Foundation が存在します。このレイヤーは、クライアントレイヤーとの接続を提供し、認証および承認チェックの実行、コンテンツの取得/処理/分析、アラート送信などの状態への対処を行います。
|
|
|
データベース: データベースレイヤーでは ThingWorx ランタイムモデルメタデータとシステムデータが管理されます。
• モデルメタデータには ThingWorx エンティティ定義、Thing 定義、および関連するプロパティ定義が含まれています。
• ThingWorx モデルに対して取得されたランタイムデータ。このデータは、ブログ、Wiki、ストリーム、値ストリーム、データテーブルのコンテンツの行として ThingWorx モデルによって永続化される表形式データまたは時系列データです。
|
ThingWorx ソリューションの機能と複雑度が増すにつれて、各層でのアーキテクチャのニーズが増大します。
以降の各セクションでは、コンポーネントが動作する層 (レイヤー) 内の ThingWorx ソリューションの各コンポーネントについて説明します。
ユーザー/クライアントコンポーネント
ThingWorx Composer またはランタイムマッシュアップを介して ThingWorx Platform にアクセスするユーザーまたはクライアントは、HTML/HTML5 をサポートする最新のブラウザ (例: Microsoft Edge、Firefox、Safari、または Chrome) を使用する必要があります。
Thing/デバイスコンポーネント
• ThingWorx Edge MicroServer - ThingWorx Edge MicroServer (EMS) は、インターネット経由で ThingWorx サーバーに接続する必要がある Edge デバイスまたはデータストアと連携して動作します。これにより、ファイアウォールの背後にあるデバイスやデータストアが ThingWorx サーバーと安全に通信し、ソリューションランドスケープに完全に参加できるようになります。ThingWorx EMS は単なるコネクタではなく、Edge に転送するデータの分析と事前処理を行えます。
• ThingWorx Edge SDK - ThingWorx Edge SDK はクラス、オブジェクト、関数、メソッド、変数の集合であり、Edge デバイスから ThingWorx Platform にデータを安全に送信可能なアプリケーションを作成するためのフレームワークを提供します。ThingWorx Edge SDK には、C、.NET、および Java プログラミング言語を使い慣れた開発者のためのツールが用意されています。
ThingWorx EMS および ThingWorx Edge SDK はプロキシ経由の接続をサポートしています。プロキシコンフィギュレーションの管理および関連する変更管理のプロセスは顧客やプロジェクトによって異なります。ThingWorx Edge SDK では、SDK ライブラリをカスタム Edge コンポーネントに含めたり任意のカスタム Edge コンポーネントから参照したりして、ソリューションの設計に基づいて更新できるので、最高の柔軟性が得られます。
プラットフォームコンポーネント
• ThingWorx Connection Server - ThingWorx Connection Server は、リモートデバイスの接続を容易にし、デバイスとの間のすべてのメッセージルーティングを処理するサーバーアプリケーションです。ThingWorx Connection Server は ThingWorx AlwaysOn 通信プロトコルを使用して WebSocket を介したスケーラブルな接続を提供します。アセットが 25,000 を超える場合、ThingWorx Foundation サーバーでの接続管理の負荷を軽減するため、接続サーバーを使用することをお勧めします。高可用性構成では、アクティブクラスタノードにデバイス接続を分散するために接続サーバーが必要です。さらに、ThingWorx Foundation サーバーへの同時接続数 100,000 につき 1 台以上の接続サーバーが推奨されます。このデバイスと接続サーバーの比率は、以下をはじめとするさまざまな要因によって変わる場合があります。
◦ デバイスの数
◦ デバイスからの書き込みサブミットの頻度
• Tomcat - Apache Tomcat は Apache Software Foundation (ASF) によって開発されたオープンソースサーブレットコンテナです。Tomcat は Oracle Corporation から提供されている Java サーブレットと Java Server Pages (JSP) 仕様を実装し、Java コードを実行するための純粋な Java HTTP Web サーバー環境を提供します。
• ThingWorx Foundation サーバー - ThingWorx Foundation はマシンツーマシン (M2M) および IoT アプリケーションのための完全な設計、ランタイム、インテリジェンス環境を提供します。ThingWorx Foundation は、接続されているデバイス、マシン、センサー、産業設備など、リモートアセットからのデータを制御およびレポートするアプリケーションを効率的に構築、実行、および拡張することを目的に設計されています。
ThingWorx Foundation は ThingWorx 環境のハブとして機能します。これに含まれているツールセットを使用して、環境にデプロイされているリモートアセット (デバイス) の動作やアセット間の関係を定義するアプリケーションを開発できます。
アセットをモデリングした後、ThingWorx Foundation に登録して通信することで、物理デバイスを監視および管理し、そこからデータを収集できます。
データベースコンポーネント
ThingWorx Platform ではプラガブルデータストアモデルが提供され、各顧客はデモやトレーニング環境のための小規模な実装から、1 秒に数千件のトランザクションをサポートする高可用性、大規模データベースまで、各自の要件に最も適したデータベースを選択できます。
値ストリーム、ストリーム、データテーブル、ブログ、Wiki が ThingWorx のデータプロバイダとして定義されています。データプロバイダはランタイムデータを保存するデータベースと見なされます。ランタイムデータとは、Thing が構成され、接続されているデバイスによって使用されてそのデータ (温度、湿度、位置など) が保存されると永続化されるデータです。Thing に関するメタデータを保存するにはモデルプロバイダが使用されます。
永続化プロバイダには、データプロバイダ、モデルプロバイダ、またはその両方が含まれます。
データベースオプションの詳細については、永続化プロバイダを参照してください。
高可用性コンポーネント
高可用性はビジネス継続性のための重要な考慮事項です。高可用性コンポーネントを効果的に運用するためには、アプリケーションレイヤーとデータベースレイヤーの両方で適用する必要があります。
ThingWorx は、ビジネスロジックとユーザーリクエストを処理する複数のアクティブサーバーノードを備えたクラスタ構成でデプロイできます。この構成はこれまでのリリースで提供されていたアクティブ-パッシブフェイルオーバー構成から置き換えられました。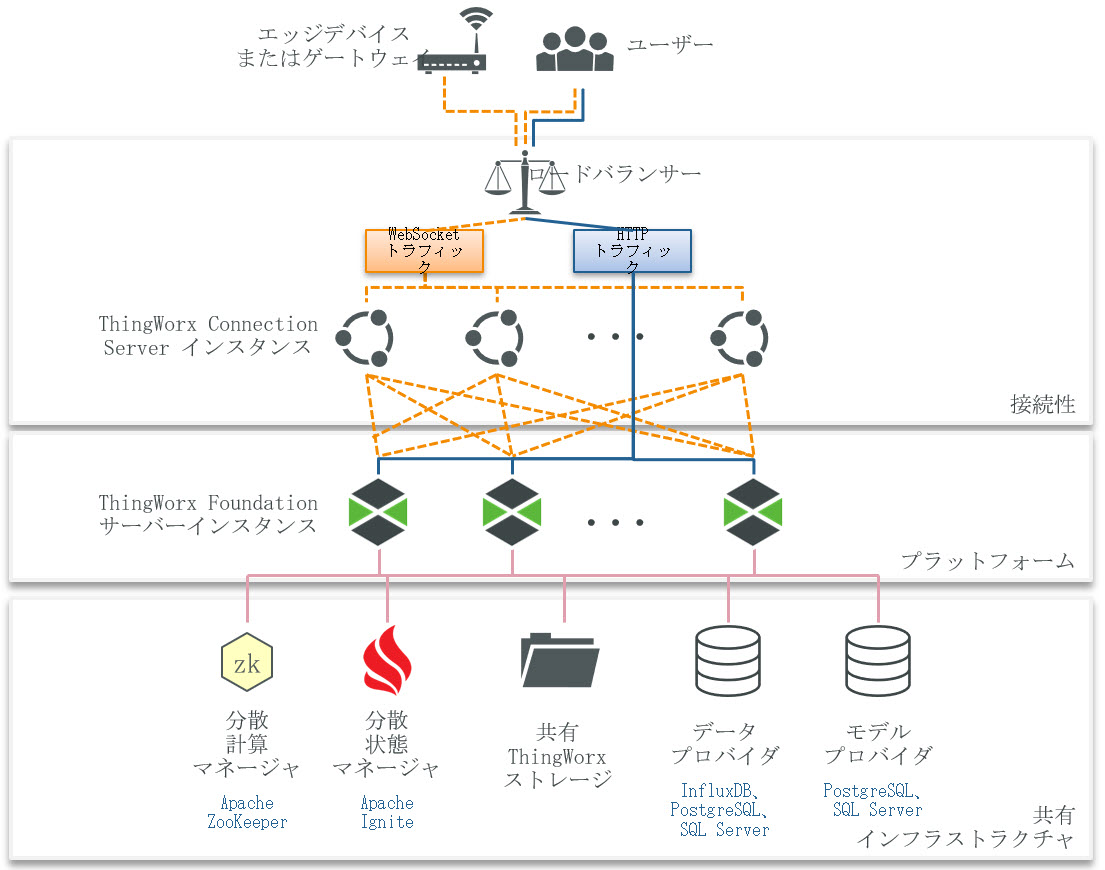
クラスタ構成では、アクティブクラスタノードにデバイス接続を分散するために接続サーバーが必要です。
ThingWorx アプリケーションレイヤーには追加のコンポーネントとして Apache ZooKeeper と Apache Ignite が必要です。高可用性データベースレイヤーの要件は、選択したデータプロバイダーのニーズによって異なります。
高可用性が真に効果を発揮するために考慮すべき事柄はソフトウェアスタックにとどまりません。電力供給、ハードディスク、ネットワークインフラストラクチャ (ルータ、ロードバランサー、ファイアウォールなど) などの冗長インフラストラクチャも評価する必要があります。 |
• ZooKeeper - Apache ZooKeeper は構成情報の管理、名前付け、分散同期化、グループサービスの提供を行う一元化されたサービスです。これは分散アプリケーションをクラスタ全体で同期化するためのコーディネーションサービスです。ThingWorx では、ZooKeeper はクラスタノードの可用性を監視するために使用され、障害が発生した場合には新しい ThingWorx Foundation リーダーノードを選出します。
• Ignite - Apache Ignite は、クラスタを構成するノード全体で大量のデータを保存および計算するために設計された、オープンソースの分散データベース/キャッシュ/処理プラットフォームです。クラスタ化された ThingWorx デプロイメントでは、Ignite を使用して、クラスタ内のすべてのノードにおけるデバイスデータの共有キャッシュを保存および管理します。
最小限のフットプリントでの HA デプロイメント
Ignite は ThingWorx Foundation プロセスに埋め込まれた状態で実行でき、その場合には別個にインストールする必要がありません。埋め込みの Ignite は、環境フットプリントがパフォーマンスよりも重要である場合にのみ使用してください。これは、高可用性のみが必要でスケール変更は必要としない小規模な環境で使用しなければなりません。これはスケーラブルではなく、パフォーマンスの問題のソリューションにはなりません。
埋め込みの Ignite における 2 サーバーのシナリオでは、唯一の利点は読み取りです。Ignite は、一部のデータをサーバー A のプライマリとしてマークし、一部のデータをサーバー B のプライマリとしてマークし、別のサーバーをデータのバックアップとしてマークします。通常、すべての読み取りがデータ用のプライマリサーバーに移動します。これはリモート呼び出しの場合もありますが、そうでない場合もあります。埋め込みの Ignite では、主な違いはバックアップからの読み取りを true に設定できることです。この場合、読み取りではネットワークのホップが発生しません。
書き込みは、同じマシンに移動することも移動しないこともあり、別のマシンへのバックアップを発生させます。したがって、書き込みにはパフォーマンス上の利点はありません。
埋め込みの Ignite を実行することで、マシンのサイズによってはパフォーマンスが低下する場合があります。単一サーバーの ThingWorx 設定と HA クラスタ内の Ignite サーバーインスタンスは以下のように異なります。
• メモリはプラットフォームで共有されます。Ignite は、プロパティメモリを保存するだけではなく、追加のキューおよびその他の Thing を追加します。
• JVM には、CPU の数に基づいていつでもアクティブにできる一定数のスレッドがあります。Ignite は、リクエスト、バックアップデータ、および一部の例外タスクを処理するために多数のスレッドを必要とします。単一サーバーの場合は、このような負荷はありません。
• キャッシュとの間で移動するすべてのオブジェクトが HA システム内のキャッシュとの間でシリアル化される一方、これは単一サーバー設定の Caffeine キャッシュレイヤーには当てはまりません。
データベースの高可用性機能
• PostgreSQL - ThingWorx はデータソリューションとして PostgreSQL 高可用性の使用をサポートしています。高可用性により、プライマリサーバーで障害が発生した場合にデータの読み取りと書き込みを取り込むサーバーを別々に設定できます。詳細については、PostgreSQL 高可用性を参照してください。
• SQL Server - 一般的に、SQL Standard Edition では必要なほとんどの機能がサポートされるので、本番用にはこれが適しています。高可用性機能、インメモリ OLTP、またはテーブルとインデックスのパーティション分割が必要な本番環境設定では、SQL Enterprise Edition が推奨されます。詳細については、Microsoft SQL Server 高可用性を参照してください。
• InfluxDB Enterprise - クラスタバージョンの InfluxDB データベースを提供します。クラスタ化によってデータを複数のノードで共有して高可用性と水平スケールの両方をサポートすることで、読み取りとクエリーを別のサーバーで実行してシステム全体のスケーラビリティを向上させることができます。新しいワークロードをサポートするためにデータノードの数を簡単に拡張できます。詳細については、永続化プロバイダとしての InfluxDB の使用を参照してください。