例 2: 少数の Thing、少数のプロパティ、高い書き込み頻度
シナリオ
例 2 のシナリオの大まかな概要
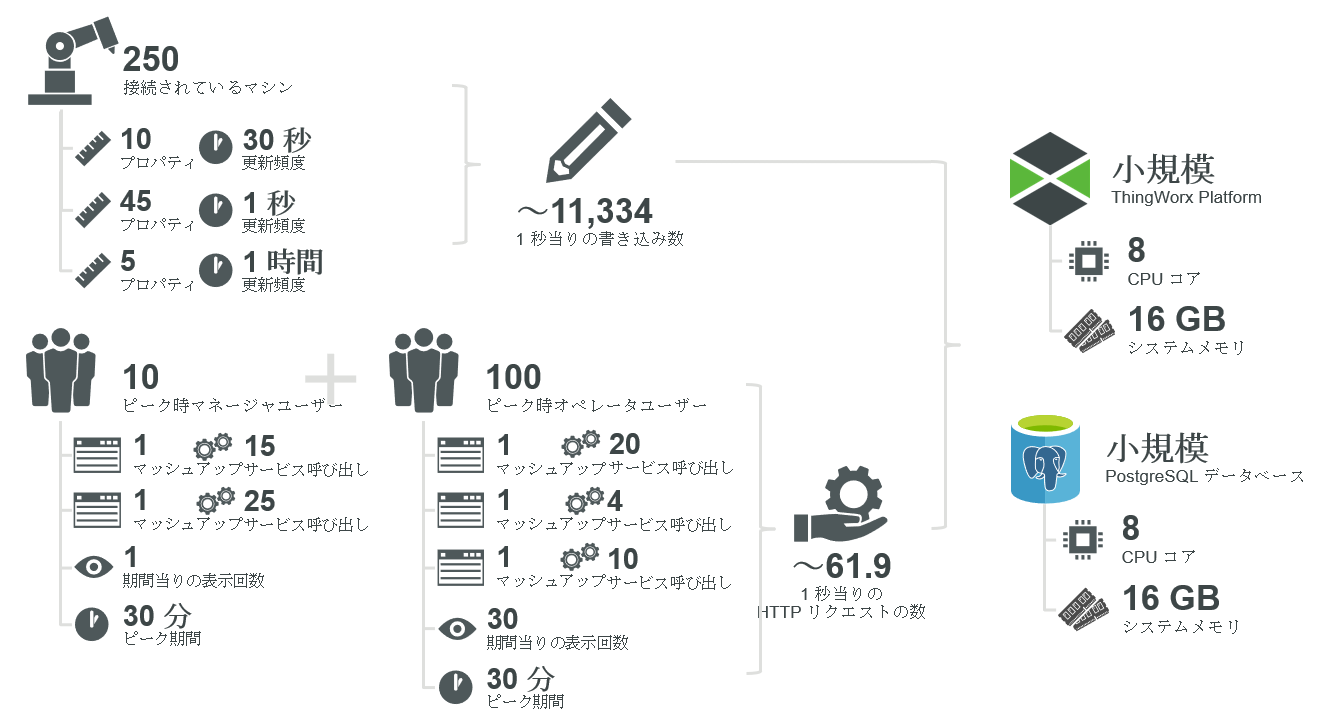
中規模の工場で、監視対象の 250 台のマシンそれぞれが異なる頻度で 60 個のプロパティの更新データを ThingWorx に送信しています (要件を参照)。
ピーク使用期間は 30 分であり、この間に 100 人のユーザーが、それぞれ異なる数のサービスで構成される 5 つの一意のマッシュアップに異なる回数の呼び出しを行います。この構成では PostgreSQL データベースが使用されています。
要件
• Thing の数 (T): 250 Thing
• プロパティの数 (P、各デバイスに 3 つの異なるプロパティグループ):
P1 | P2 | P3 |
|---|---|---|
10 プロパティ | 45 プロパティ | 5 プロパティ |
• 書き込み頻度 (F):
F1 | F2 | F3 |
|---|---|---|
30 秒に 1 回 (1 日当り 2,880 回) | 1 秒に 1 回 (1 日当り 86,400 回) | 1 時間に 1 回 (1 日当り 24 回) |
• ピーク使用期間 (t) = 30 分 (1800 秒)
• マッシュアップの数 (M) = 5 マッシュアップ
• ユーザー数 (UM):
UM1 | UM2 | UM3 | UM4 | UM5 |
|---|---|---|---|---|
100 ユーザー | 100 ユーザー | 100 ユーザー | 10 ユーザー | 10 ユーザー |
注記: ユーザーリクエストの数が少ないマッシュアップは管理ユーザー用の共通マッシュアップです | ||||
• マッシュアップ当りのサービスの数 (SM):
SM1 | SM2 | SM3 | SM4 | SM5 |
|---|---|---|---|---|
20 サービス | 4 サービス | 10 サービス | 15 サービス | 25 サービス |
• ユーザーが各マッシュアップをロードする回数 (LM):
LM1 | LM2 | LM3 | LM4 | LM5 |
|---|---|---|---|---|
30 回 | 30 回 | 30 回 | 1 回 | 1 回 |
注記: 30 回とは、30 分のピーク期間中に、おそらくは自動再表示によって、1 分ごとにマッシュアップ 1、2、3 が再ロードされることを示しています。 | ||||
計算
• データ取得:
WPS = T × [(P1 × F1) + (P2 × F2) + (P3 × F3)]
= 250× [(10 × 1/30) + (45 × 1) + (5 × 1/3600)]
≈ 11,334 writes per second
= 250× [(10 × 1/30) + (45 × 1) + (5 × 1/3600)]
≈ 11,334 writes per second
これはプロパティ書き込みの頻度が異なるのでやや複雑です。必要に応じて、FD を 86,400 で割ることで秒に変換できます。
接続サーバーの値も計算することを忘れないでください。
CS = T / 100,000
= 250/ 100,000
= 0.0025 Connection Servers
= 250/ 100,000
= 0.0025 Connection Servers
• データビジュアリゼーション:
R = [(SM + 1) × UM × LM ] / t
R1 = [(20 + 1) × 100 × 30 ] / 1800
≈ 35 requests per second
R2 = [(4 + 1) × 100 × 30 ] / 1800
≈ 8.33 requests per second
R3 = [(10 + 1) × 100 × 30 ] / 1800
≈ 18.33 requests per second
R4 = [(15 + 1) × 10 × 1 ] / 1800
≈ 0.09 requests per second
R5 = [(25 + 1) × 10 × 1 ] / 1800
≈ 0.14 requests per second
R = R1 + R2 + R3 + R4 + R5
≈ 61.89 requests per second
R1 = [(20 + 1) × 100 × 30 ] / 1800
≈ 35 requests per second
R2 = [(4 + 1) × 100 × 30 ] / 1800
≈ 8.33 requests per second
R3 = [(10 + 1) × 100 × 30 ] / 1800
≈ 18.33 requests per second
R4 = [(15 + 1) × 10 × 1 ] / 1800
≈ 0.09 requests per second
R5 = [(25 + 1) × 10 × 1 ] / 1800
≈ 0.14 requests per second
R = R1 + R2 + R3 + R4 + R5
≈ 61.89 requests per second
このシナリオでは、マッシュアップによってサービスの数が異なり、その一部は少数のユーザーによって呼び出されます。また、1 分ごとに再表示されるものと、1 回だけロードされるものがあります。
この場合、LM を見落とさないようにしてください。自動再表示によるマッシュアップのサービスの追加の呼び出しは、システムのサイジングに大きな影響を与える可能性があります。
この計算には多くの要素が含まれていますが、マッシュアップごとの式に分解してから結果を合算 (上の図) するのが簡単です。
基準の比較
• T = 250 -> "極小規模" プラットフォーム (またはそれ以上、PostgreSQL 使用)
• CS = 0.0025 -> 接続サーバーは不要
• WPS = 11,334 -> "小規模" プラットフォーム (またはそれ以上)
• R = 61.89 -> "中規模" プラットフォーム (またはそれ以上)
サイジング
すべての基準を満たすには "中規模" ThingWorx システムが必要ですが、ホストのタイプに基づいて、以下のサイズを検討する必要があります。
サイズ | Azure VM | AWS EC2 | CPU コア | メモリ (GiB) |
|---|---|---|---|---|
ThingWorx Platform: 中規模 | F16s v2 | C5d.4xlarge | 16 | 32 |
PostgreSQL DB: 中規模 | F16s v2 | C5d.4xlarge | 16 | 32 |
計算された結果と実際の結果の比較
例 2 では、それぞれ異なる頻度で再表示される、さまざまなサービス呼び出しを行う複数のマッシュアップから成る実際のアプリケーションをシミュレーションし、シミュレーション対象の Remote Thing がさまざまな頻度でプラットフォームにデータを送信しています。
インフラストラクチャの観点からは、プラットフォームの平均の CPU 使用率は 34.8 %、メモリ消費量は 3.1 GB で、パフォーマンスは良好でした。PostgreSQL の平均の CPU 使用率は 35.1 %、メモリは 8.1 GB でした。
プラットフォームの観点からは、HTTP リクエストレートは 1 秒当りの平均が 63 オペレーションであり、これは想定した 62 オペレーションとほぼ一致しています。1 秒当りの値ストリームキュー書き込み回数は実際に 12 k WPS 付近で安定し、前述の想定した 11.3 k WPS 以上に近い状態です。
例 2 のシミュレーションされたデプロイメントでの実際の結果
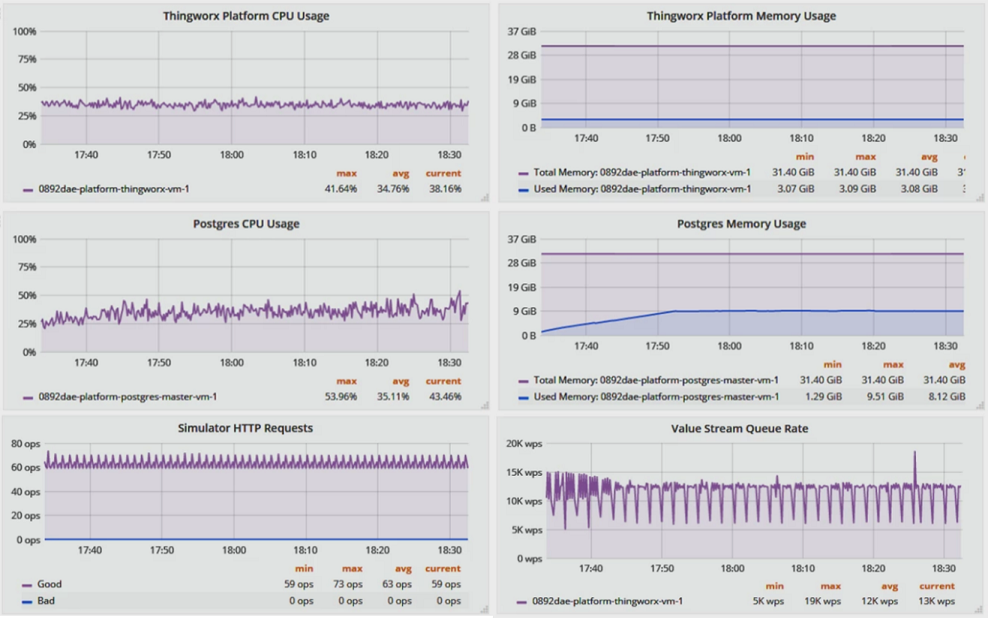
アプリケーションまたはユーザーの観点からは、エラー、パフォーマンスの問題、不正なリクエスト/応答がデバイスまたはユーザーのシミュレータによって検出されませんでした。新しいリクエストはすべて適切なタイミングで処理されました。
上の図に示すように、この実装には、シミュレーションされた定常状態のワークロードと、デバイス/ユーザーアクティビティでのより現実的なスパイクの両方に対応するのに十分なリソースがあります。