Hochverfügbarkeit mit PostgreSQL
PostgreSQL 11 muss seine Daten auf allen Knoten synchronisieren, damit jeder Knoten aktuell ist, wenn er Lese- oder Schreibanforderungen erhält. Es gibt keine einzelne Lösung, um potenzielle Synchronisierungsprobleme zu beseitigen. Daher sind viele Optionen für die Hochverfügbarkeit (High Availability, HA) zu bedenken. Ein Vergleich von HA-Lösungen für PostgreSQL 11 ist hier als Liste im Tabellenformat verfügbar: https://www.postgresql.org/docs/11/different-replication-solutions.html.
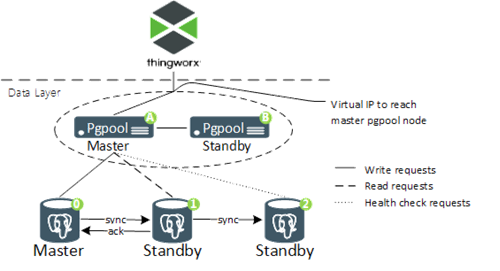
Das folgende Diagramm zeigt die von PTC empfohlene Konfiguration für eine PostgreSQL-HA-Bereitstellung.
PostgreSQL
ThingWorx kann eine große Menge an Inhalt in die Datenbank schreiben, und es ist wichtig, die Schreibsequenz auf allen PostgreSQL-Knoten intakt zu halten. PTC empfiehlt, alle PostgreSQL-Knoten für die synchrone Replikation in einer kaskadierenden Replikationsarchitektur zu konfigurieren und dabei mit den Einschränkungen zu arbeiten, die für die synchrone Replikation gelten. Für diese Option gelten die folgenden Anforderungen:
• Es müssen drei gleich große PostgreSQL-Serverknoten bereitgestellt werden.
◦ Ein Masterknoten, an den Schreibanforderungen geleitet werden. Der Master streamt WAL-Datensätze an einen Standby-Knoten und führt Transaktionen nur aus, wenn der Standby-Knoten diese bestätigt hat.
◦ Ein Standby-Knoten, der den Streaming-Inhalt vom Master empfängt. Außerdem streamt er den Inhalt an einen zweiten Standby-Knoten.
◦ Ein zusätzlicher Standby-Knoten, der den Streaming-Inhalt vom ersten Standby-Knoten empfängt. Sollte ein Knoten ausfallen oder offline gehen, ist dieser Knoten einer der beiden verbleibenden, der weiterhin den von Master- und Standby-Knoten bestätigten Streaming-Prozess ausführt.
pgpool-II
Um die PostgreSQL-HA-Konfiguration abzuschließen, müssen Schreib- und Leseanforderungen an den richtigen Knoten weitergeleitet, die Knotenintegrität muss überwacht und fehlerhafte Knoten müssen offline geschaltet und repariert werden. PTC empfiehlt pgpool-II, um diese Aufgaben auszuführen. Für diese Option gelten die folgenden Anforderungen:
• Zwei gleich große pgpool-Serverknoten müssen bereitgestellt werden. Sie arbeiten in einem aktiv/passiv-Modus.
◦ Ein Knoten fungiert als Master. Er leitet Schreibdatenverkehr an den PostgreSQL-Masterknoten und Lesedatenverkehr an den PostgreSQL-Standby-Knoten weiter.
◦ Ein Knoten wird als Standby-Knoten ausgeführt. Er übernimmt bei einem Fehler des pgpool-Masterknotens die Verteilung des Datenverkehrs.
• Eine virtuelle IP-Adresse wird von den pgpool-II-Knoten verwaltet. Der Master verwendet diese Adresse, um den PostgreSQL-Datenverkehr von Clients zu empfangen.
Hinweise zu pgpool-II:
• Pgpool-II wird in einer Windows-Umgebung nicht unterstützt.
• Cloud-Implementierungen von PostgreSQL verwenden möglicherweise einen direkten DNS-Failover-Mechanismus anstelle von pgpool-II.
• Sie können einen pgpool-II-Prozess auf demselben Server wie die ThingWorx Anwendung ausführen, um die Gesamtzahl der Server in einer HA-Umgebung zu reduzieren.
• PTC empfiehlt nicht, pgpool-II für die Verwaltung der PostgreSQL-Replikation zu verwenden. Bei den in diesem Dokument bereitgestellten Anleitungen werden die Streaming-Replikation von PostgreSQL und pgpool-II für die Weiterleitung von Datenverkehr, die Überwachung der Knotenintegrität und die Failover-Automatisierung verwendet.