K-fold Validation
What is K-fold Validation?
K-fold validation is a cross-validation technique that can provide a more accurate estimate of how well models created from a dataset will perform. As an alternative to validating on a holdout set of data, the k-fold validation method is particularly useful for small datasets where reserving a holdout portion of data for validation can be undesirable.
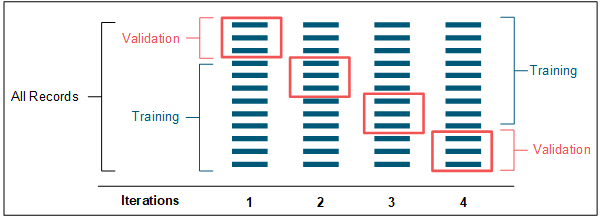
When k-fold validation is invoked, as part of a training or validation job, the data is partitioned into (approximately) equally-sized subsets, or folds. The k in k-fold validation stands for the number of folds the data is partitioned into. The k number of data subsets are trained and validated as k separate models. Each data subset is used as a validation set for one model. All subsets that are not used for validation of a specific model (k – 1 folds) are used for training that model. In this way every record is used for validation only once and no record is ever used to train and validate the same model. The image below illustrates how this cross-validation works.
|
|
Some time-series data is an exception to this partitioning rule. See the next section.
|
Because k-fold validation is an iterative process, it can impact Analytics Server performance.
How is Data Partitioned for K-fold Validation?
The method used for partitioning data for k-fold validation depends on the type of data in question.
• Non-time series data
For non-time series data, the splitting is performed randomly and each fold contains an equal number of records. The image below illustrates the random splitting.

• Multi-entity time series data
For time series data from multiple entities, the splitting is performed randomly by entity. All data from a specific entity is included in a single fold and each fold contains records from an approximately equal number of complete entities. In this scenario, the number of entities included in the time series data must be at least as large as the number of folds. The image below illustrates random splitting by entity.
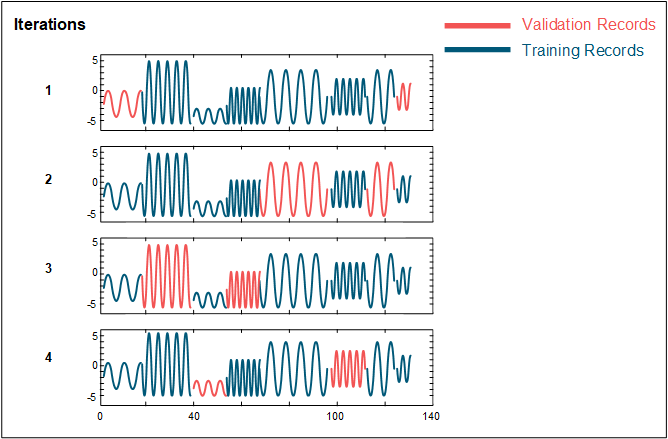
• Single-entity time series data
For time series data from a single entity, the splitting is performed via forward chaining. The data is split into k + 1 contiguous, equally-sized folds. The first model is trained on the data in fold 1 and validated on fold 2. The second model is trained on the data in folds 1 and 2, and validated on fold 3. The process continues until the final model is trained on the data in folds 1 through k and is validated on fold k + 1. The image below illustrates data splitting via forward chaining.
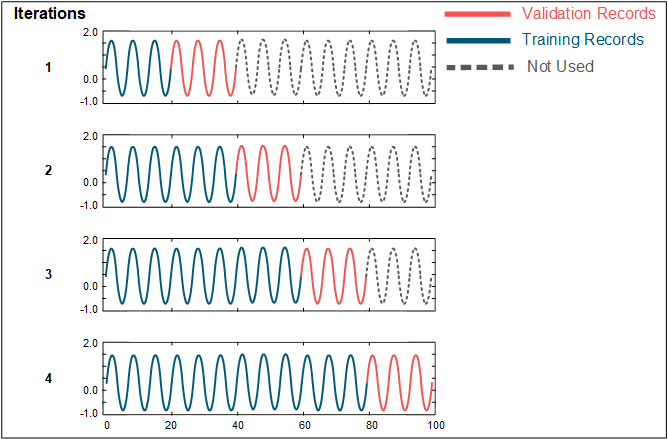
K-fold Validation Results
When k-fold validation is used, model results include the same metrics you would see when using a holdout validation set, such as ROC, RMSE, RMSE Normalized, Pearson Correlation, MCC, or Accuracy. However, instead of a single set of metrics for the entire dataset, a set of metrics is returned for each of the k folds the data was partitioned into.
In addition to the list of folds, with their individual metrics, a set of statistics is calculated across the folds. These statistics include a mean, standard deviation, min, max, and a count for each metric. In some scenarios, where a metric might be undefined, the count statistic reflects how many folds were used in the calculation for that metric. For a sample of the k-fold validation results file structure, see the image below.
To avoid data leakage between folds, all training transformations are performed using values (for example, normalization constants) that are computed separately on the training set for each fold, after excluding that fold’s validation set.
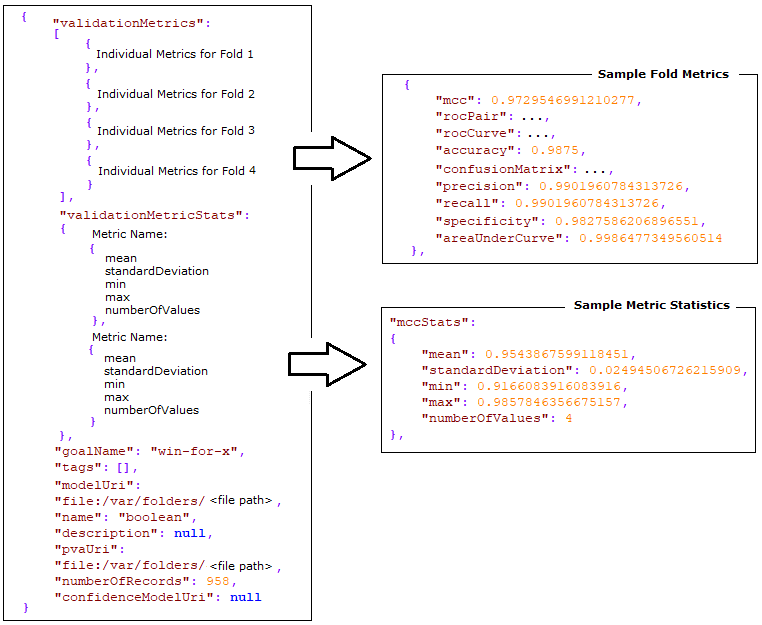
How to Access K-fold Validation Functionality
Beginning with release 9.3, k-fold validation can be accessed via Analytics Server APIs, using either ThingWorx Composer or a REST client. K-fold validation can be invoked by including a numberOfFolds parameter in jobs run by the Validation or Training services of the Async microservice. Values for numberOfFolds can range from 2 to 20, inclusive.
• Validation Job – When a numberOfFolds value is specified for a validation job, k-fold validation is performed instead of validating on a holdout set of data. The model configuration is retrieved using a provided model URI and models with that configuration are trained on each fold.
The model used must be ThingWorx Analytics model and cannot be a user-uploaded model. |
• Training Job – When a numberOfFolds value is specified for a training job, the model is trained on all of the data. Then a validation job is invoked with the specified number of folds. Using the URI for the trained model, the validation job performs k-fold validation as described above. If the validateOnTraining option is selected, a second validation job is invoked as usual on the training set, which is the entire dataset in this scenario. The results of the second validation job contain the usual single metric values and no statistics.
Requires installation of both ThingWorx Foundation and ThingWorx Analytics Server.
K-fold validation is not currently available in Analytics Builder.