Configuración de la herramienta de carga de CSV y carga de datos
Antes de empezar
Antes de empezar, asegúrese de disponer de la siguiente información:
• Ubicación remota para cargar el fichero comprimido (.zip) de datos CSV
• URL de conexión, nombre de usuario y contraseña de Task Manager
Por ejemplo: http://dominio.nombre/TaskManager/
• Ruta UNC a la ubicación del fichero .zip CSV
• Ruta UNC a la carpeta Assets
Se encuentra en INICIO_INSERVICE\InS_SW\SW\System\Assets.
• URL de conexión, nombre de usuario y contraseña de la instancia de Viewer de vista previa de Servigistics InService
Por ejemplo: http://sitiovistaprevia.dominio.nombre/InService/delivery/
• URL de conexión, nombre de usuario y contraseña de la instancia de Viewer en tiempo de ejecución de Servigistics InService
Por ejemplo: http://sitiotiempoejecución.dominio.nombre/InService/delivery/
Carga de datos SIM/SP al mismo tiempo que datos CSV
En los siguientes casos, es posible cargar datos Windchill Service Information Manager y Windchill Service Parts (SIM/SP) al mismo tiempo que los datos CSV:
• Carga de contenido de recopilaciones específicas mediante los datos CSV, mientras que otras recopilaciones se cargan a través de la SIM
• Combinación de la jerarquía de productos (PH) a partir de los datos SIM/SP y CSV
Si primero se cargan los datos CSV, defina el valor de las propiedades number y objNumber en el fichero product_Hierarchy.xml del paquete de SIM/SP en ROOT PRODUCT. ROOT PRODUCT se encuentra en el fichero de propiedades INICIO_INSERVICEInS_SW\Config\Applications\DataProcess\Config\Common\Templates\CSVToInService\CSV2InService.properties.
Si los datos SIM/SP se cargan primero, cambie la siguiente propiedad en el fichero CSV2InService.properties a este valor:
ph.root='objNumber'
• Combinación de elementos de información (IE), tales como IEXML, PDFM y GRAPHICS, de SIM/SP y CSV
Los elementos de información se identifican la SIM mediante la propiedad uri, de la siguiente manera:
Los elementos de información se identifican en los datos CSV mediante códigos de la siguiente manera:
Para identificar los elementos de información de manera exclusiva, la asignación se debe definir entre el objeto uri y los códigos. La asignación se realiza en la sección de origen CSV del fichero IMANConfig.xml, de la siguiente manera:
Por ejemplo, supongamos que el paquete SIM/SP se carga primero y que contiene un IEXML con un objeto uri definido en x-wc://file=0000016040.xml. A continuación, se carga un paquete CSV con la siguiente asignación en el fichero xml.csv:
En este caso, la columna de código XML tiene el mismo valor uri que el IEXML de SIM/SP, por lo que este IEXML se identifica con el mismo ID que se ha cargado con el paquete SIM/SP.
• Cargar tipos de LDM a partir de los datos CSV y cargar otro contenido mediante SIM/SP
Por ejemplo, supongamos que se carga el primer paquete SIM. Es entonces cuando el paquete CSV se carga con los siguientes datos de bomcollections.csv:
En este caso, la segunda entrada corresponde a un tipo de LDM de un paquete SIM/SP. El contenido de esta entrada debe añadirse al fichero properties.csv de la columna ContextIds, tal como se indica a continuación:
• Cargar solo las instancias de producto mediante los datos CSV y cargar el otro contenido mediante SIM/SP
• Cargar los artículos y las relaciones de artículos (incluidos los kits) mediante los datos CSV y cargar el resto del contenido mediante SIM/SP
Se debe tener en cuenta la siguiente información acerca del proceso para carga de datos SIM/SP al mismo tiempo que los datos CSV:
• La práctica recomendada es cargar primero los datos SIM y, a continuación, los datos CSV.
De este modo, se pueden buscar y utilizar los valores de uri de SIM en la asignación CSV.
• Es posible cargar los datos de la tabla de contenido de la estructura de información (IS) desde la SIM o el CSV, pero no desde ambos.
• En el momento que se utilicen ambos paquetes SIM/SP y CSV, es importante tener en cuenta la secuencia de carga ya que el origen se actualiza según la prioridad definida en el fichero IMANConfig.xml.
Task Manager
Los datos CSV se transforman y cargan en Servigistics InService mediante la tarea Transform and Load CSV Data en Task Manager. Antes de convertir y cargar datos, se deben definir las diferentes recopilaciones según el contexto del producto definido en el fichero properties.csv. Cargue los datos CSV en formato comprimido en el sitio remoto proporcionado de modo que esté disponible para Task Manager. Inicie sesión en Task Manager utilizando el URL de conexión, el nombre de usuario y la contraseña proporcionados.
Pasos de configuración y carga de datos
Para cargar datos CSV, se debe crear como mínimo una recopilación de artículos. Además de esta recopilación, se debe crear una recopilación para cada recopilación que se especifique en el fichero properties.csv.
Siga estos pasos para configurar y cargar los datos CSV:
1. Inicie sesión en Task Manager.
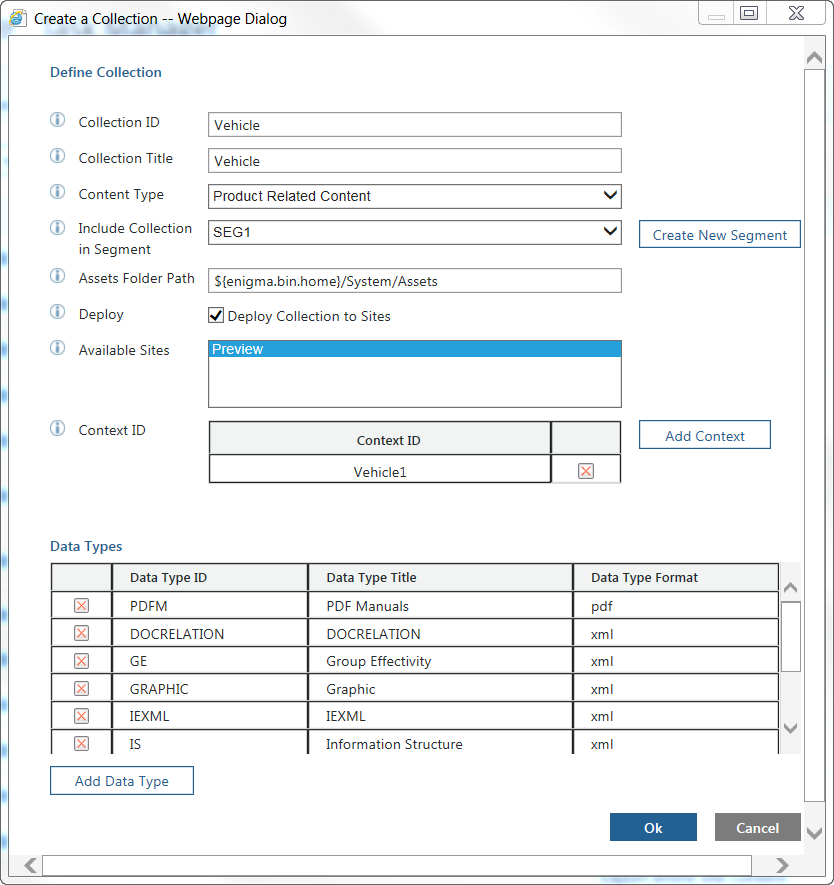
2. Utilice la tarea Add Collection para crear la recopilación definida en el fichero properties.csv con la siguiente información:
◦ Collection ID y Collection Title, tal como se define en properties.csv.
◦ Assets Folder Path: ubicación de la ruta de activos.
◦ Available Sites: seleccione Preview solo para Sandbox y Preview y Runtime para producción.
◦ Context ID similar a Collection ID.
◦ Data Types: PDFM, DOCRELATION, GE, GRAPHIC, IEXML, IS, PH, PI, PS y PARTSLIST.
Se debe tener en cuenta que si se cargan los ficheros de una instancia de producto o una LDM, también se debe incluir el tipo de datos de LDM.
Por ejemplo:
3. Si se publica en el grupo del sitio Runtime, utilice la tarea Transform and Load CSV Data para cargar el fichero .csv del paquete CSV en la instancia de Viewer de tiempo de ejecución con la siguiente información:
◦ Input Path (obligatorio): ruta UNC al fichero ZIP o ubicación de la carpeta CSV.
◦ Site Groups: tiempo de ejecución.
◦ Pause after transform: false
◦ PI only: false
◦ Convert CGM to SVG: false
◦ Load to Publication Manager Only: false
4. Si se publica en el grupo de sitios Preview, utilice la tarea Publish To Sites para cargar el fichero .csv del paquete CSV en esa instancia de Viewer con la siguiente información:
◦ Equipment: PARTS y la recopilación.
◦ Manual: todo.
◦ Site Groups: vista previa.
| Este paso y el siguiente paso solo son necesarios la primera vez que se publique datos en el grupo del sitio Preview. |
5. Utilice la tarea Publish To Sites para cada recopilación a fin de mover los datos de la instancia de Viewer de vista previa a la instancia de Viewer en tiempo de ejecución con la siguiente información:
◦ Collection ID: PARTS y la recopilación del usuario
◦ Site Group: tiempo de ejecución
6. Verifique que los datos se hayan cargado correctamente en Servigistics InService.
Se puede verificar la carpeta INICIO_INSERVICE\InS_Data\Work\DCTM_Output para ver los datos.
Datos de salida
La carpeta de salida se define automáticamente en DCTM_Output en el directorio de la herramienta. La salida de contenido está lista para la carga en el formato DCTM_Output.
Configuración adicional
Puede ser necesaria la siguiente configuración adicional:
• Configure el fichero Characters_mapping.xml.
Este fichero se encuentra en INICIO_INSERVICE\InS_SW\Config\Applications\DataProcess\Config\Common\Templates\CSVToInService. Normalmente, se documentan las asignaciones de todos los objetos utilizados para generar ficheros XML de origen. Si en los nombres de fichero se incluyen caracteres especiales (por ejemplo, & o #), los caracteres se reemplazan según se especifica en este fichero de asignaciones.
• Configure el fichero CSV2InService.properties.
Este fichero se encuentra en INICIO_INSERVICE\InS_SW\Config\Applications\DataProcess\Config\Common\Templates\CSVToInService. Este fichero se utiliza para combinar datos de PH cuando se cargan datos SIM/SP y CSV.