多変量多項式回帰の統計量
• polyfitstat(X, Y, n/"terms"/M, [conf]) - 行列 Y に格納されている結果を行列 X 内のデータに適合させることで、多項式回帰モデルの統計量データを返します。多項式回帰式を定義するには、その多項式次数 n を指定するか、文字列 “terms” または行列 M にその項を指定します。多項式適合に切片を含めない場合、行列 M を使用します。デフォルトの 95% 以外の信頼区間を指定するには、オプションの引数 conf を使用します。
polyfitstat によって返される行列の 2 列目には次の要素が格納されています。
|
行
|
説明
|
|---|---|
|
1
|
Y の標準偏差
|
|
2, 3, 4
|
R2、adjusted R2, and predicted R2
|
|
5
|
PRESS - 予測誤差の二乗和 (残差の尺度化に使用)
|
|
6
|
自己相関に関する Durbin-Watson 検定統計量
|
|
7
|
回帰係数の行列 (polyfitcによって返されるものと同じ)
|
|
8
|
回帰モデルの ANOVA の行列。その列には anova によって返される統計表と同じ要素が格納され、行には次の要素が格納されています。
• 回帰 - (切片) を除く各項の小計
• 残差 (誤差) - Lack of Fit 検定による誤差と単なる実験上の誤差の小計
• 回帰モデルの合計
|
|
9
|
次の列から成る診断の行列:
1. 各ランまたはデータ点の番号
2. 各ランまたはデータ点の観測結果
3. 調査中の回帰モデルによる予測結果
4. 残差 - 観測結果と予測結果の差
5. てこ比 - 観測結果からすべての観測結果の中心点までの距離の指標
6. スチューデント化残差 - 観測結果に基づく分散によって残差を割った値
7. 外的スチューデント化残差 - 観測結果が除去されたデータセットに基づく分散によって残差を割った値
8. クック距離 - 観測結果がその他すべてのデータ点に与える影響の指標
9. DFFITS - 観測結果が含まれているデータセットに基づいた回帰モデルによる予測結果と、観測結果が除去されたデータセットに基づいた回帰モデルによる予測結果の差。
|
引数
• X は、各列が独立変数を表す計画行列または行列です。X の各列の単位には整合性がなければなりません。
• Y は、X で定義されている各ランまたはデータ点の結果が各行に含まれている、測定結果またはシミュレーション結果のベクトルまたは行列です。すべての行でレプリケートの数が同じでない場合、Y の空の要素を NaN で埋める必要があります。Y の各要素の単位には整合性がなければなりません。
• n は多項式次数を指定する整数です。これはデータ点の総数より小さくなければなりません (1 ≤ n ≤ length(Y) − 1)。そうでない場合、問題の制約条件が不十分となり、一意な解を得ることができません。
• “terms” は、多項式回帰に含める項 (因子と交互作用) を指定する文字列引数です。"A B AB AA BB" は、多項式に次の項が含まれていることを意味します。
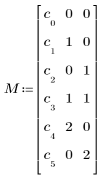
c0 + c1 ∙ A + c2 ∙ B + c3 ∙ A ∙ B + c4 ∙ A2 + c5 ∙ B2
区切り文字として、スペース、コンマ、コロン、セミコロンを使用できます。
• M は多項式を指定する行列であり、その 1 列目には係数の推定値を指定し、その他の列には各項の独立変数のべき数を指定します。上記の多項式では、M を次のように定義します。
• conf (オプション) は必要な信頼限界であり、パーセント表記ではなく 0 以上 1 以下の小数表記で指定します。デフォルトは、95% の信頼区間 conf = 0.95 です。