|
행
|
설명
|
|
1
|
Y의 표준 편차
|
|
2, 3, 4
|
R2, 조정된 R2 및 예측된 R2
|
|
5
|
PRESS - 예측 오차 제곱합(잉여값 배율 조정에 사용)
|
|
6
|
자기상관에 대한 더빈-왓슨(Durbin-Watson) 검사 통계값
|
|
7
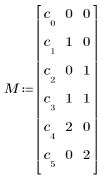
|
polyfitc로 구한 회귀 계수의 행렬
|
|
8
|
anova로 구한 결과 표와 열이 동일하고 행이 다음과 같은 회귀 모델의 분산분석 행렬
• 회귀 - 부분합(절편을 제외한 각 항에 대해 추가 분할)
• 잉여값(오차) - 부분합(낮은 적합도 오차와 순수 실험 오차로 추가 분할)
• 회귀 모델에 대한 합계
|
|
9
|
열이 다음과 같은 진단 행렬
1. 각 실행(Run) 또는 데이터 점에 대해 매긴 번호
2. 각 실행(Run) 또는 데이터 점에 대해 관측한 결과
3. 조사 대상인 회귀 모델을 통해 예측한 결과
4. 잉여값(Residual) - 관측한 결과와 예측한 결과 사이의 차이
5. 지렛대값(Leverage) - 관측한 결과와 모든 관측 결과 중심에 놓여 있는 점 사이의 간격에 대한 측정치
6. 스튜던트화된 잉여값(Studentized residual) - 관측한 결과에 기반하여 분산으로 나눈 잉여값
7. R 스튜던트(R-student) - 관측 결과가 제외된 데이터 집합에 기반하여 분산으로 나눈 잉여값
8. 쿡의 거리(Cook’s distance) - 관측한 결과가 다른 모든 데이터 점에 미치는 영향에 대한 측정치
9. DFFITS - 관측 결과가 포함된 데이터 집합에 기반하여 회귀 모델을 통해 예측한 결과와 관측 결과가 제외된 다른 모델을 통해 예측한 결과 사이의 차이
|