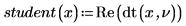예제: 데이터 벡터의 T 점수
지정된 평균을 기준으로 정규 분포 데이터의 벡터에 대한 t 점수를 계산합니다.
1. 분석할 데이터의 벡터를 정의합니다.
2. 표본 통계를 수집합니다.
표본 수 | | |
표본 평균 | | |
표본 표준 편차 | | |
평균의 표준 오차 | | |
자유도 | | |
3. 유의 수준과 추정 모집단 평균을 정의합니다.
4. t 점수를 계산합니다.
5. 귀무가설 및 대립가설을 기술합니다.
H0: m ≤ μ
H1: m > μ
6. p-value를 계산하고 가설을 검증합니다.
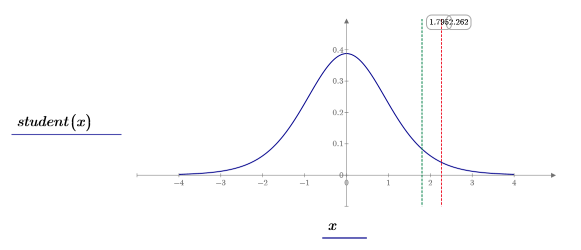
귀무가설이 참이라고 가정하면 테스트 통계가 관측 통계보다 클 확률이 0.106입니다. p-value와 유의 수준을 비교해 보면 대립가설이 참이라는 증거가 없다는 것을 알 수 있습니다.
7. 임계 영역의 한계를 계산하고 가설을 검증합니다.
귀무가설을 승인합니다. 평균이 μ보다 크다는 증거가 없습니다.
8. 스튜던트 t 분포(파랑), 임계 영역의 경계(빨강) 및 t 점수(녹색)를 도표화합니다.