|
Zeile
|
Beschreibung
|
|
1
|
Die Standardabweichung für Y
|
|
2, 3, 4
|
R2, R2 angepasst und R2 vorhergesehen
|
|
5
|
PRESS – Vorhergesehene Fehlersumme der Quadrate (Prediction Error Sum of Squares) (nützlich für die Skalierung von Residuen)
|
|
6
|
Durbin-Watson-Teststatistik für Autokorrelationen
|
|
7
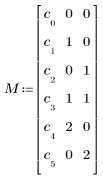
|
Matrix der Regressionskoeffizienten wie von polyfitc zurückgegeben
|
|
8
|
ANOVA-Matrix für das Regressionsmodell mit Spalten, die mit der von anova zurückgegebenen Ergebnistabelle übereinstimmt und folgende Zeilen aufweist:
• Regression – Teilsumme, die dann für jeden Term (ausgenommen intercept) aufgeschlüsselt wird
• Residuum (Fehler) – Teilsumme, die dann zwischen dem Passungsfehler und dem reinen Versuchsfehler aufgeschlüsselt wird
• Summe für das Regressionsmodell
|
|
9
|
Diagnosematrix mit folgenden Spalten:
1. Nummerierung für jeden Rechenlauf und Datenpunkt
2. Beobachtetes Ergebnis für jeden Rechenlauf und Datenpunkt
3. Von dem zu untersuchenden Regressionsmodell vorhergesagtes Ergebnis
4. Residuum – Differenz zwischen dem beobachteten und dem vorhergesagten Ergebnis
5. Hebelwirkung – Messung des Abstands zwischen dem beobachteten Ergebnis und dem Punkt in der Mitte aller beobachteten Ergebnisse
6. Student-verteiltes Residuum – Residuum dividiert durch die Varianz basierend auf dem beobachteten Ergebnis
7. R-Student – Residuum dividiert durch die Varianz basierend auf einem Datensatz, wobei das beobachtete Ergebnis entfernt wird
8. Cook-Abstand – Messung des Einflusses des beobachteten Ergebnisses auf alle anderen Datenpunkte
9. DFFITS – Differenz zwischen den von einem Regressionsmodell auf Basis eines Datensatzes mit inkludiertem beobachteten Ergebnis vorhergesagten Ergebnis und dem von einem anderen Modell, bei dem das beobachtete Ergebnis entfernt wurde, vorhergesagten Ergebnis
|