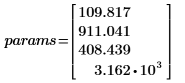예제: 기울기 연산자
• 함수 f를 정의합니다.
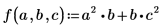
기울기 연산자를 사용하여 f에 대한 편도함수의 벡터를 받습니다.
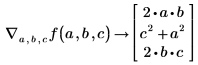
• 벡터 함수를 정의하고 벡터 x로 함수 f의 기울기를 계산합니다.
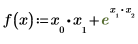

이 예제에서는 모든 배열의 시작 지수를 설정하는 ORIGIN이 0으로 설정되어 있습니다.
f의 아래 첨자가 가장 큰 변수는 x2입니다. Mathcad는 x0, x1, x2라는 세 변수가 있다고 가정합니다. 그 결과 이 변수의 편도함수를 포함하는 세 개의 값으로 구성된 기울기 벡터를 구할 수 있습니다. f에 x0 또는 x1 중 하나가 나타나지 않은 경우에도 Mathcad는 여전히 세 개의 값으로 구성된 벡터를 반환하지만, 누락된 변수에 해당하는 항목은 0으로 설정됩니다.
f에 나타나는 아래 첨자 중 가장 큰 n에 대해 Mathcad는 x0, x1, ... xn이라는 n + 1개의 변수를 가정하여 그 길이 n + 1의 벡터를 반환합니다.
• x를 수치적으로 정의하면 등호 =로 기울기를 계산할 수 있습니다. Mathcad는 x의 값에서 기울기를 계산하여 점 x에서의 기울기를 나타내는 숫자 벡터를 구합니다. x의 길이는 f에 나타나는 가장 큰 아래 첨자보다 커야 하며 Mathcad는 길이(x) 항목의 기울기를 반환합니다.
다음 예제에서 x0 및 x1은 식에 나타나는 유일한 변수로, Mathcad는 x0 및 x1을 기준으로 편도함수를 사용하여 값이 두 개인 벡터를 구합니다.
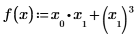
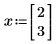
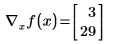
그러나 x를 요소가 3개인 벡터로 정의하는 경우 Mathcad는 식에 나타나지 않는 추가 변수 x2가 있다고 가정합니다. 그 결과 3개의 요소로 구성된 벡터를 반환합니다.
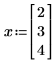
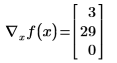
genfit 함수에 기울기 연산자 사용하기
기울기 연산자는 genfit 함수에 인수를 설정하는 데 특히 유용하며 이는 데이터 집합에 대한 일반 비선형 함수에 적합합니다.
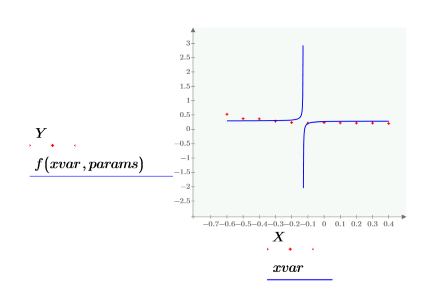
• 다음 표의 데이터를 사용합니다.
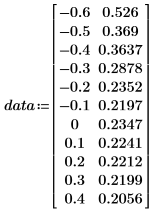
• 첫 번째 열에는 데이터의 x 값이 있고 두 번째 열에는 y 값이 있습니다.
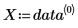
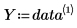
• 다음 형식의 함수로 데이터를 모델링합니다.
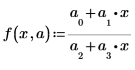
여기에서 a1, a2, a3는 벡터 a에 포함된 알 수 없는 매개 변수입니다.
다음과 같이 genfit을 호출하여 데이터를 모델링할 수 있습니다.
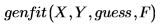
이 식에서
◦ X와 Y는 데이터의 x 값과 y 값을 포함하는 벡터입니다.
◦ guess는 매개 변수에 대한 초기 추측값으로 구성된 벡터입니다.
◦ F는 첫 번째 항목이 모델 함수 f(x, a)이고 나머지 항목은 알 수 없는 매개 변수에 대한 f의 편도함수인 벡터입니다.
• 기울기 연산자와 stack 함수를 사용하여 벡터 F를 만듭니다.
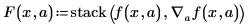

• stack 함수는 기울기 연산자로 만든 편도함수 벡터 위에 모델 함수 f를 배치합니다.
• 그런 다음 매개 변수의 추측값 벡터를 만듭니다.
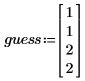
• 다음과 같이 genfit을 적용합니다.
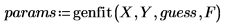
• 최적합을 제공하는 매개 변수는 다음과 같습니다.