![[Integration Kit What's New]](../../Nav02_WhatsNew.png "Integration Kit What's New")
| |
From version 2007 (v15) onwards, Creo Elements/Direct Modeling uses Unicode/ISO10646 as its character set for string data. The preferred encoding for strings in memory is UTF-16 (Unicode Transformation Format 16-bit).
A character set is just a list of characters. The characters in this list are often indexed so that you can easily refer to them by number, but the index is not necessarily identical with the byte values which are used to represent the character in memory or in files.
Here's an example: If we can trust Babelfish, "success" translates to two
Kanji characters in Japanese, 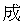 and
and 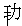 . In the JIS X 0208 character set, these characters have "tuple
indices" of (32,14) and (24,89). If we encode these characters in Shift-JIS
(the prevalent encoding in Japan) and look at the bytes in memory, however,
we see byte sequences of 0x90 0xAC and 0x8C 0xF7, respectively.
. In the JIS X 0208 character set, these characters have "tuple
indices" of (32,14) and (24,89). If we encode these characters in Shift-JIS
(the prevalent encoding in Japan) and look at the bytes in memory, however,
we see byte sequences of 0x90 0xAC and 0x8C 0xF7, respectively.
Shift-JIS (often also called SJIS) is an encoding of the Japanese character set, i.e. it is one of many ways to represent Japanese characters in memory. It's important to know the difference between a character set and an encoding: The character set (in the example: JIS X 0208) defines which characters are available and can be represented at all. The encoding (in the example: Shift-JIS) is a detailled recipe of how to represent a character in memory or in a file - a mapping from a set of characters into a memory representation.
Unicode, or more officially ISO10646, is a character set. The Latin alphabet is a character set, and JIS X 0208 is a character set, too.
In contrast, SJIS is an encoding for the Japanese character set. ISO8859-1 is an encoding for the Latin alphabet (plus a bunch of other characters thrown in for good measure). HP-Roman8 is another encoding for the Latin alphabet & friends. And UTF-16 is one of several encodings used for Unicode characters. In UTF-16, most characters in practical use (those from the Basic Multilingual Plane) are represented by one 16-bit word. More recent additions to the Unicode character set are encoded using a sequence of two 16-bit words (which are then called a surrogate pair).
Joel Spolsky's The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!) is a highly recommended introduction which discusses the subject of character sets and encodings in more detail.
Before OneSpace Modeling 2007, it was assumed that strings were either
European and encoded in HP-Roman8, or Japanese and encoded in Shift-JIS.
(HP-Roman8 was chosen for European locales because it used to be the default
encoding in HP-UX, i.e. it is a remnant of the origins of Creo
Elements/Direct Modeling.) Creo Elements/Direct Modeling had no reliable way
of verifying this encoding assumption at runtime: Does the byte value 0xE0
represent a French Á (Roman8), or the first byte of the
two-byte Japanese character  (Shift-JIS)? Is 0xCC a German ä (Roman8), or
is it the half-width Katakana
(Shift-JIS)? Is 0xCC a German ä (Roman8), or
is it the half-width Katakana 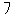 (Shift-JIS, pronounced "fu")? To avoid such
confusion, customers were strongly recommended never to load non-Japanese
data into a Japanese version of Creo Elements/Direct Modeling and vice
versa.
(Shift-JIS, pronounced "fu")? To avoid such
confusion, customers were strongly recommended never to load non-Japanese
data into a Japanese version of Creo Elements/Direct Modeling and vice
versa.
In Unicode, every character in the world has its own unique code position and cannot be confused with other characters. This allows Creo Elements/Direct Modeling to safely load string data of all proveniences into the same session. We can have Japanese and German and French and Chinese and Arabian and Hindi part names in the same model. Better still, we can have multiple languages within a single string!
This is because Unicode is a character set which lists characters from almost all languages. In the Unicode catalogue, there's space for well over 1 million characters; much of the catalogue's pages are, in fact, still empty, waiting to be filled with newly invented, extinct, obscure or extra-terrestrial characters. Anyway - all the actively spoken and used languages are covered!
Products using Unicode are no longer limited to just Latin or Japanese or Chinese or whatever characters - in a relatively short amount of time, support for any language can be added, with hardly a code change anywhere in the product!
A note of warning: Currently, only characters from the so-called Basic Multilingual Plane (BMP) are officially supported, i.e. the first 65536 code positions defined by the Unicode standard. We plan to improve support for surrogate pairs in future releases of Creo Elements/Direct Modeling.
The Common Lisp standard requires that any implementation supports at least 96 standard characters, which are essentially identical with the 96 printable characters in the ASCII range (0-127). Common Lisp implementations are, however, free to support more characters than that.
The character data type in Creo Elements/Direct Modeling's implementation of Lisp has been upgraded to 16 bits in OneSpace Modeling 2007. All Lisp characters and strings are now encoded in UTF-16. All Lisp functionality which deals in some way with characters, strings, or arrays of characters now understands UTF-16. This includes the Lisp reader and loader.
The following demo program displays a full page of characters (i.e. 256 characters) in the output box. Any of the 256-character "pages" in the Unicode standard can be selected for display. decodeunicode.org is a good guide to some of the more interesting places in the standard.
(defun code-position(page row column)
(+ (* page 256) (* row 16) column))
(defun my-code-char(codeposition)
(if (graphic-char-p (code-char codeposition))
(code-char codeposition)
(code-char 63)))
(defun display-page(page-number)
(dotimes (i 16)
(display
(with-output-to-string (s)
(format s "~X " (code-position page-number i 0))
(dotimes (j 16)
(format s " ~C "
(my-code-char (code-position page-number i j))))))))
Load this code into Creo Elements/Direct Modeling, then try a few pages:
(display-page 0) ;; ISO8859-1 subset of Unicode (display-page 3) ;; diacritics, Greek and Coptic (display-page 4) ;; Cyrillic (display-page 6) ;; Arabic (display-page 48) ;; Hiragana and Katakana
The Common Lisp function code-char is used to convert an integer value into the corresponding Unicode character; and graphic-char-p checks whether that particular character is actually printable. The rest of the code example is rather boring, but at least it produces some pretty exotic output:
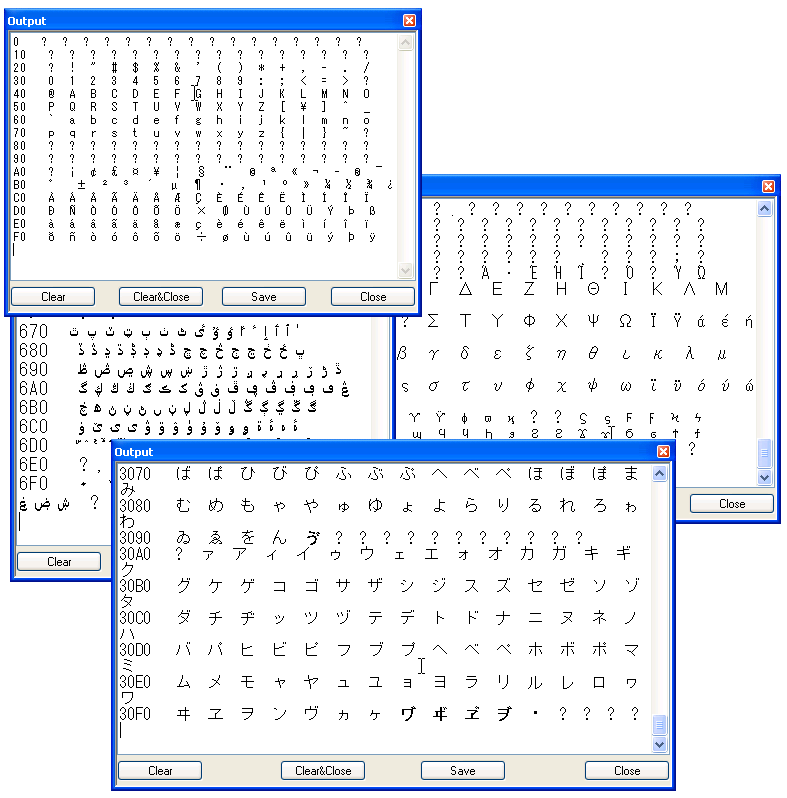
The text in the output box appears a little cluttered because of variable-width fonts, but the code shows that Creo Elements/Direct Modeling can display and process characters from such a variety of languages within one and the same session!
 Chances are that when you try this on your system, all you
get is empty boxes instead of characters. The reason is that most UI fonts
only cover a few selected scripts; for example, the popular fixed-width
"Courier" and "Courier New" fonts are sufficient to display most Latin
characters including all kinds of accented characters and umlauts, but won't
support Cyrillic, Hebrew, or Asian languages.
Chances are that when you try this on your system, all you
get is empty boxes instead of characters. The reason is that most UI fonts
only cover a few selected scripts; for example, the popular fixed-width
"Courier" and "Courier New" fonts are sufficient to display most Latin
characters including all kinds of accented characters and umlauts, but won't
support Cyrillic, Hebrew, or Asian languages.
So in order to actually see such characters, you may have to install additional system fonts first. For Unicode coverage, fonts like "MS Gothic" or "MS UI Gothic" are good choices. If those fonts are not already available on your test system, Microsoft provides a download package which contains them. Other sources for Unicode fonts:
To find out which kind of characters are supported by any given font, use
Microsoft's charmap.exe utility which ships with Windows. To run the tool,
simply enter charmap in a DOS prompt window.
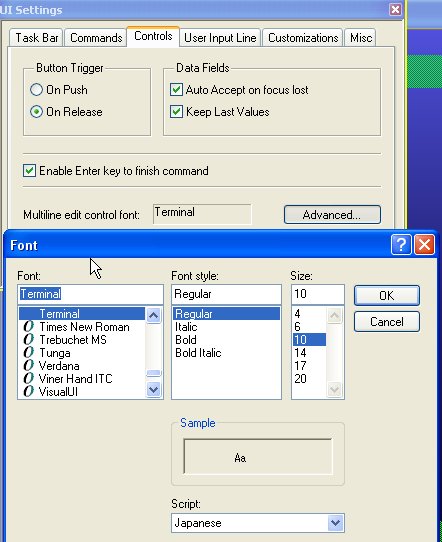
Even with the right fonts installed in the system, in some cases you may have to explicitly change the font used for multiline edit controls in Creo Elements/Direct Modeling. This can be accomplished by opening the "UI Settings" dialog via "Edit/Settings", going to the "Controls" tab and selecting a font which covers a wider range of characters from the Unicode standard than the fonts which are selected by default.
Where speed matters, Creo Elements/Direct Modeling will try to avoid any encoding conversions during file I/O and save strings directly in Creo Elements/Direct Modeling's internal encoding, i.e. UTF-16. For example, environment and PDS files use UTF-16 encoding, as well as native Creo Elements/Direct Modeling model files.
However, files which are likely to be viewed and edited by users, such as
recorder files, are usually written in UTF-8, which is another
encoding commonly used for text files containing Unicode characters. UTF-8
files are easier to work with using traditional tools which are not or not
fully Unicode-aware, such as command shells, grep,
awk and many editors.
Also, Creo Elements/Direct Modeling exchanges data with a lot of external applications and data sources, which may expect encodings other than the ones used internally in Creo Elements/Direct Modeling (UTF-16). Examples:
So even though internal character handling is greatly simplified in OneSpace Modeling 2007 (since all characters are allowed now, and a single encoding, UTF-16, is used consistently), some conversions will still remain necessary when exchanging data with other applications. Which conversion is required in each particular case, depends on the receiving end and its preferences. The Integration Kit provides all the functionality required to convert from and to a variety of popular string encodings.
Lisp's (open) function has been extended to support automatic encoding
conversions in stream I/O. When writing to or reading from a file, you can
specify the file's encoding using the :external-format
keyword:
(let ((s (open "foo.html" :direction :output :external-format :utf-8))))
(write-html-header s)
(format s "<body>foo</body>~%")
(write-html-trailer s)
(close s))
;; slightly more elegant alternative:
(with-open-file (s "foo.html" :direction :output :external-format :utf-8)
(write-html-header s)
(format s "<body>foo</body>~%")
(write-html-trailer s))
Any output that goes to the stream s will be converted
automatically. The full list of supported encodings can be found here. The most important
ones are:
:legacy |
This is the encoding which the old, non-Unicode versions of Creo
Elements/Direct Modeling would use in a given locale. Most useful
for communicating with older versions of Creo Elements/Direct
Modeling or Creo Elements/Direct Drafting.
|
:system |
The encoding which Windows chooses by default for non-Unicode
applications; this encoding depends on the operating system
language. Most useful when communicating with external non-Unicode
Windows components and applications.
|
:locale |
The Windows encoding which matches the current Creo Elements/Direct Modeling language. |
:internal |
The encoding used internally in Creo Elements/Direct Modeling.
Equivalent to :utf-16 in OneSpace Modeling 2007 and
later. |
:utf-8 |
UTF-8 encoding, does not write a BOM (byte-order marker, see below) into the output file. Typically used for XML or HTML files which specify file encodings using meta tags rather than by writing a BOM. |
:utf-8-bom |
Same as :utf-8, but writes a BOM. |
:utf-16 |
UTF-16 (little-endian) encoding; writes a BOM. |
What exactly is this "BOM" mentioned above? The BOM, or byte-order marker, is a "magic" byte sequence at the beginning of a file which contains text encoded in UTF-8 or UTF-16. It is used for two purposes:
The UTF-16 BOM is either the byte sequence 0xFF 0xFE (little-endian) or 0xFE 0xFF (big-endian). The UTF-8 BOM is 0xEF 0xBB 0xBF.
When reading from a file, specifying :default or no
:external-format at all instructs Lisp to auto-detect the
encoding used in the input. If the file starts with a BOM, the BOM type will
determine the encoding (i.e. UTF-8 or UTF-16). If no BOM is found in the
input, :legacy encoding is assumed.
The encoding of an already opened stream can be inquired using (stream-external-format).
What if you want to open a file and make sure that no automatic
conversion whatsoever is performed, i.e. you want truly binary I/O? This is
what open's :element-type keyword is for:
(with-open-file
(s :direction :output :element-type '(unsigned-byte 8))
(write-byte 42 s))
(load) also supports the :external-format keyword,
and the same encodings can be used as with (open). So if you
need to load a Lisp file in ISO8859-1 encoding, you can accomplish this as
follows:
(load "iso8859-1.lsp" :external-format :iso8859-1)
The Lisp loader will automatically convert the input into the internal string representation.
If you don't specify an :external-format, Lisp will try to
auto-detect the encoding using the same rules as for
(open):
:utf-8 encoding is
assumed.:utf-16 encoding is
assumed.:legacy encoding is assumed, which maximizes
compatibility with existing Lisp files.If you know that your Lisp code contains non-ASCII string or character
literals and makes certain assumptions about the encodings of those strings,
it makes sense to document this assumption by using (load) with
an explicit :external-format specification, rather than relying
on the default behavior - especially since automatic encoding conversions
can have subtle implications. The following table illustrates what
legacy encoding means exactly for some particular language versions
of Creo Elements/Direct Modeling.
| Creo Elements/Direct Modeling language | Legacy encoding |
|---|---|
| German | HP-Roman8 |
| English | HP-Roman8 |
| French | HP-Roman8 |
| Japanese | Shift-JIS |
| Chinese (Traditional) | Big5 |
So when you run Creo Elements/Direct Modeling in Japanese, legacy
encoding means Shift-JIS. All Lisp files which Creo Elements/Direct
Modeling loads will be assumed to use Shift-JIS string encoding by default,
except where stated otherwise using the :external-format
keyword. In a German version of Creo Elements/Direct Modeling, however, all
Lisp files which are loaded are assumed to encode strings in HP-Roman8 by
default.
But what if the same Lisp file is loaded both into the Japanese and the German version of Creo Elements/Direct Modeling? How can the same Lisp file be encoded both in Shift-JIS and in HP-Roman8?
The answer is that it can't, unless it settles on the common subset covered by both encodings - which can only be ASCII, i.e. the range from 0-127, because HP-Roman8 and Shift-JIS use a wildly different and conflicting interpretation of the code points from 128-255. What looks like an accented character when interpreted in HP-Roman8, may be a Katakana character or the first byte of a two-byte Kanji character in Shift-JIS encoding.
As an example, the byte value 0xE0 is interpreted as à in ISO8859-1, but as Á in Roman8. When interpreted as part of a Shift-JIS string, the same byte value is the first byte of roughly 200 different two-byte Kanji characters (examples: 蹯, 沈).
Ambiguities like this can be avoided if the Lisp file starts with a BOM
(which indicates the encoding), or if you use the
:external-format keyword. But if there are no such hints, the
Lisp loader must guess - and this guess is based on which language version
of Creo Elements/Direct Modeling the user is running. If the Lisp file
contains Roman8-encoded umlauts, and you're loading the Lisp file into a
German version of Creo Elements/Direct Modeling, everything works as
expected. But if you load the same Lisp file into the Japanese version of
Creo Elements/Direct Modeling, strings in the file will be misinterpreted,
leading to runtime errors, corrupted data, or both.
Bottom line: Legacy-encoded Lisp files should not contain any characters but those from the ASCII range except if you can control precisely in which language version they are loaded. This is not a new restriction, by the way; it applies to older, non-Unicode versions of Creo Elements/Direct Modeling as well.
There are several ways to handle the issue:
:external-format keyword in
(load).Most string conversion needs should be covered by the capabilities
provided by (open). But sometimes, you need more explicit
control, such as in test code. Strings can also be converted from one
encoding to another in memory using the new APIs (oli:sd-string-to-octets)
and (oli:sd-octets-to-string).
(oli:sd-string-to-octets) takes a string and converts it
into an integer array:
(setf utf8-array (oli:sd-string-to-octets "somestring"
:external-format :utf-8))
Why is the output an integer array? Because Lisp strings are always in UTF-16; they simply cannot hold any other encoding. But integer arrays do not really know much about characters and their meanings anyway, and so we can stuff into them any data we want.
(oli:sd-octets-to-string) can be used for the reverse
direction.
(oli:sd-recode-textfile)
converts a whole text file from one encoding to another. Since the
conversion can take some time for long files, we recommend to use this
function mainly for one-time conversions of legacy files rather than in
functionality which end users are likely to run often.
Older string conversion functions such as (oli:sd-internal-to-display-string),
and (oli:sd-display-to-internal-string) no longer actually
convert anything; they simply copy their input. We'll keep those APIs around
for a while so that legacy applications won't break. But those functions are
now obsolete and should no longer be used.
Prior to OneSpace Modeling 2007 (v15), strings which potentially contain user input or messages were marked as so-called extended strings, upon which only a limited amount of string operations could be performed. This is similar to how Perl assumes every variable which may contain user input as tainted, and requires them to be untainted explicitly before they can be processed.
This mechanism was invented because only a subset of the Lisp functionality could handle multibyte characters safely. This restriction has been lifted in OneSpace Modeling 2007, and the extended and simple string types have been unified. Basically, the extended string type doesn't exist anymore.
With these changes, any Common Lisp string functionality can be used on any kind of Lisp string, regardless of its content or origin. This is a significant improvement for application writers who now have the full gamut of Common Lisp functionality at their disposal, and no longer have to explicitly learn about string processing APIs specific to Creo Elements/Direct Modeling.
Because there is no longer an extended string type, (oli:sd-ext-string-p)
will always return nil.
If you're writing code which needs to run both in Unicode and non-Unicode versions of Creo Elements/Direct Modeling (for example, for both v15 and v14), you should still follow the old rules for extended strings, i.e. restrict yourself to the limited set of string processing functions which know how to handle extended strings.
If you need to use non-ASCII characters in Lisp code, save the Lisp file in UTF-8 or UTF-16 encoding.
Always encode the file in UTF-8 or UTF-16 encoding if it
contains a call to (oli:sd-multi-lang-string)
or (ui::multi-lang).
When opening files in Lisp using (open),
(with-open-file) or (load), provide hints about
the file encoding with the :external-format keyword.
Do not use strings in mixed encodings within the same file.
If you need to review non-trivial amounts of Lisp code for potential Unicode issues, use the string API scanner utility which ships with OneSpace Modeling 2007 and later. This tool will point out code areas which use obsolete API calls or potentially questionable string processing techniques:
To activate the string API scanner code, enter the following:
(load "stringapiwalker")
To scan a Lisp file c:/temp/foo.lsp, enter the following command:
(stringapiwalker::walk-file "c:/temp/foo.lsp"
:logfile "c:/temp/walkfile.log")
The precise syntax for walk-file is as follows:
(stringapiwalker::walk-file infile
&key (logfile nil) (external-format :default))
If no logfile is specified, the scanner output goes to the console window. Lisp files in encodings other than HP-Roman8 can be inspected by explicitly specifying their encoding using the :external-format keyword. Example:
(stringapiwalker::walk-file "foo_utf8.lsp" :logfile "c:/temp/walkfile.log"
:external-format :utf-8)
To scan Lisp code, it must be loadable and compilable, i.e. it must be free of syntax errors and package conflicts.
Checking c:/temp/foo.lsp for obsolete string processing...
About to check top-level form
(LISP::IN-PACKAGE :ARGL)
About to check top-level form
(LISP::USE-PACKAGE :OLI)
WARNING: Found non-ASCII string literal: "fäöüß"
Recommendation: Non-ASCII characters should only be used in Lisp files
which are encoded in either UTF-8 or UTF-16.
WARNING: Found non-ASCII string literal: "fäöüß"
Recommendation: Non-ASCII characters should only be used in Lisp files
which are encoded in either UTF-8 or UTF-16.
WARNING: Found non-ASCII string literal: "fäöüß"
Recommendation: Non-ASCII characters should only be used in Lisp files
which are encoded in either UTF-8 or UTF-16.
About to check top-level form
(LISP::DEFUN ARGL::ARGL (ARGL::ARGLMODE)
(LISP::PRINT "fäöüß")
(FRAME2-UI::DISPLAY "fäöüß")
(LISP::WHEN ARGL::ARGLMODE
(FRAME2-UI::DISPLAY (OLI::SD-INTERNAL-TO-DISPLAY-STRING "fäöüß"))))
WARNING: Found string processing function
SD-INTERNAL-TO-DISPLAY-STRING in
(OLI::SD-INTERNAL-TO-DISPLAY-STRING "fäöüß")
Recommendation: This API no longer performs any conversion
and is considered obsolete. Please consult the IKIT
reference documentation (section on string handling) for details
on how to convert between string encodings.
If your code must make a distinction between Unicode and non-Unicode
versions of Creo Elements/Direct Modeling, you can check for the
lisp:unicode feature at runtime:
(when (si::eval-feature 'lisp:unicode)
(run-unicode-tests))
It might be tempting to try and replace
(sd-internal-to-display-string) and
(sd-display-to-internal-string) in legacy code with
"equivalent" calls to (sd-string-to-octets) and
(sd-octets-to-string), but this is rarely, if ever, the right
approach. Instead, consider using (open) or (load)
with the right :external-format specification.
For example, you may have some Lisp code which reads in a configuration
or data file which was produced by an external tool which wrote its output
in ISO8859-1. Let us further assume that your existing Lisp code uses
(open) and (read-line) to read those data, and
then converts each line using
(sd-display-to-internal-string):
(with-open-file (s "config.txt" :direction :input)
(let (line)
(loop while (setf line (read-line s nil nil)) do
(setf line (oli:sd-display-to-internal-string line))
(do-something-with-line line))))
This should be converted to:
(with-open-file
(s "config.txt" :direction :input :external-format :iso8859-1)
(loop with line while (setf line (read-line s nil nil)) do
(do-something-with line line)))
If a text file starts with a BOM, it is trivial to determine the string encoding in the file. For files without a BOM, however, determining the string encoding in a file is a complex task. Because of the inherent ambiguities of encodings, the only practical general approach is to analyse the input file for the frequency of certain codes and code combinations, and to compare the result with known frequencies for certain languages and encodings.
In the context of Creo Elements/Direct applications, however, certain assumptions can be made which have a high chance for success:
The following code snippet implements this approach:
(defun inq-file-encoding(filename)
(with-open-file (s filename :direction :input)
(stream-external-format s)))
Not all editors or development environments fully support UTF-16, and for those which do, some configuration may be necessary to be able to enter and display characters in UTF-8/16 style.
For correct handling of Unicode files, the following functionality is required:
Alan Wood maintains a great web site where he also lists Unicode editors, both commercial and non-commercial. In the following, we'll discuss just a few editors which we have tested at least briefly at PTC.
One of the editors which we currently recommend is Notepad++, a compact open-source editor which handles both UTF-8 and UTF-16 files correctly. A customized version of Notepad++ ships with Creo Elements/Direct Modeling, and if Notepad++ is installed on the system, Creo Elements/Direct Modeling will use it as its default external editor. The customized version which we ship includes special syntax highlighter files for Creo Elements/Direct Modeling Lisp and Creo Elements/Direct Drafting macro language.
Ships with Windows. Recognizes UTF-8 and UTF-16 files automatically. Does not properly write UTF-8 BOMs, and has known bugs when loading UTF-8 files, therefore not recommended.
Ships with Windows. Doesn't understand Unix-style line endings. Seems to handle UTF-16 and UTF-8 properly, but functionality is too limited to really use it for serious editing.
Notepad is one of the editors which use a process called "Unicode sniffing" - it looks at the contents of a file and heuristically deduces its encoding even if the file does not start with a BOM. Sometimes Notepad guesses wrong. An amusing experiment: Run Notepad and type "this api can break". Now save the text as a file and load it back into Notepad - you'll get a few empty boxes (or Chinese characters if you happen to have the right fonts installed). The reason? Notepad doesn't know the encoding in the file, so it tries to guess it, using heuristical and statistical reference data - and "identifies" the text as being encoded in UTF-16 (which it is not).
vim and gvim
handle both UTF-8 and UTF-16 correctly. Add the following to your
.vimrc file:
:set encoding=utf-8 :set bomb
In gvim, the font used for displaying characters can be set
via Edit/Select Font. More on encoding support in vim can be
found here.
EmacsW32 (v22 and later) and XEmacs (v21.5 and later) have the required functionality to support both UTF-8 and UTF-16 files.
Visual Studio handles both UTF-8 and UTF-16 files. See also "Visual Studio How to: Manage Files with Encoding".
ConTEXT basically seems to work, but isn't as convenient to use in a Unicode environment as other editors.
While testing code for compatibility with multiple languages, it helps to know how to enter characters from those languages even if all you have is a US keyboard.
The most trivial way to enter foreign characters is to copy and paste them. There are millions of web sites out there with foreign-language content. All you need to do is to surf to one of them, copy some of the displayed text into the clipboard and paste it into Creo Elements/Direct Modeling! Excellent sources for copying and pasting text are the local language versions of Wikipedia: Arabic, Czek, French, Japanese and Chinese, it's all right there, at your fingertips.
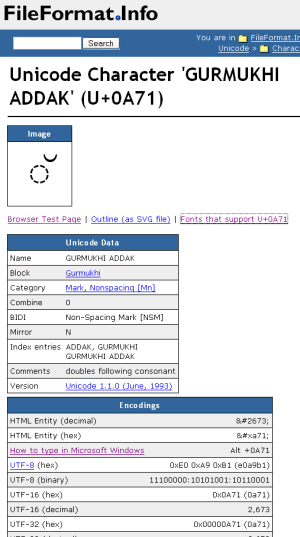 Sometimes, you may be hunting for a special Unicode character of which you
know its official Unicode name or its codepoint. Two web sites are
particularly useful in such a case: Bernd Nies' Unicode
tables list the whole range of characters from U+0000 to U+FFFF - and
the characters in those tables are displayed as text and not as images,
which means that you can copy and paste them directly from the table.
Sometimes, you may be hunting for a special Unicode character of which you
know its official Unicode name or its codepoint. Two web sites are
particularly useful in such a case: Bernd Nies' Unicode
tables list the whole range of characters from U+0000 to U+FFFF - and
the characters in those tables are displayed as text and not as images,
which means that you can copy and paste them directly from the table.
Even more information about each and every Unicode character can be found at www.fileformat.info/info/unicode/char/search.htm: How you write the character in various programming languages such as Java, Python, C++, or HTML; the character's encoding representation in UTF-8, UTF-16 and UTF-32; hints on how to type the character in Windows, and a lot more.
Windows has several built-in ways to enter arbitrary characters, even if you don't happen to have a keyboard for the particular language.
Two very simple methods involve the ALT key and the numeric keypad: Press the ALT key and hold it, now enter a 0 (the digit), followed by a Unicode codepoint value in decimal; all the digits used for the value must be entered on the numeric keypad! Now release the ALT key.
If you'd rather enter the codepoint value in hexadecimal, run
regedit and use it to create a new REG_SZ key called
EnableHexNumpad at the registry path HKEY_CURRENT_USER\Control
Panel\Input Method, and give it a string value of "1"; now reboot the
system. From now on, you can enter hexadecimal Unicode codepoints using this
sequence:
Some may find the following method slightly easier:
write without
arguments in a DOS prompt window), or open Creo Elements/Direct Modeling's
output boxThe four digits preceding the cursor position will now be converted into the Unicode character which they represent. Copy and paste from the WordPad or output box window into any Creo Elements/Direct Modeling text input field, and you're done!
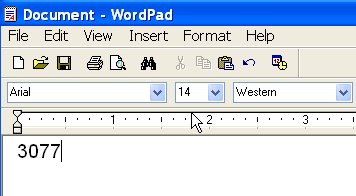 Before pressing Alt-X |
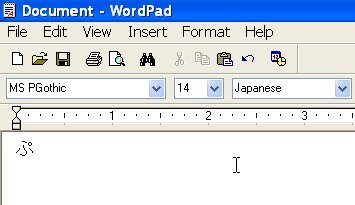 After pressing Alt-X; notice how WordPad automatically selected a matching font and set the language to "Japanese". |
Input method editors (IMEs) are little applets which hook into Windows and help with entering characters in all kinds of languages. One such IME, the Unicode IME, is particularly useful since it doesn't require us to master any particular language, such as Chinese, but allows simple hexadecimal input.
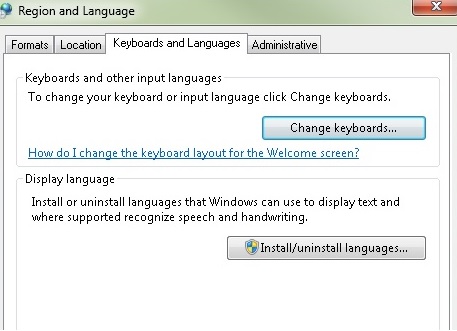 To install this IME on a Windows 7 system, go to the Control Panel
and open the "Region and Language Settings". Change into the "Keyboards and
Languages" tab. Go to the "Keyboards and Languages" tab of the "Region and
Language Settings" dialog and press "Change keyboards...". Press "Add..." in
the "Text Services and Input Languages" dialog. This pops up the "Add Input
Language" dialog.
To install this IME on a Windows 7 system, go to the Control Panel
and open the "Region and Language Settings". Change into the "Keyboards and
Languages" tab. Go to the "Keyboards and Languages" tab of the "Region and
Language Settings" dialog and press "Change keyboards...". Press "Add..." in
the "Text Services and Input Languages" dialog. This pops up the "Add Input
Language" dialog.
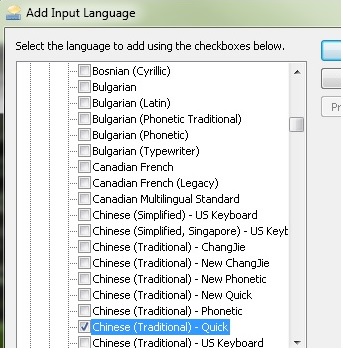 In
the list of languages , look for an entry called "Chinese (Unicode)". If it
isn't there, select "Chinese (Traditional, Taiwan)" instead, expand that
entry, then check the checkbox for "Chinese (Traditional) - US Keyboard" and
close all open dialogs.
In
the list of languages , look for an entry called "Chinese (Unicode)". If it
isn't there, select "Chinese (Traditional, Taiwan)" instead, expand that
entry, then check the checkbox for "Chinese (Traditional) - US Keyboard" and
close all open dialogs.
 Now you can toggle between normal English input and Chinese input by
pressing the left ALT key plus the shift key. (You can also configure this
to CTRL-Shift instead.) There's an indicator for the current input language
in the taskbar. Once you're in Chinese mode, simply start entering sequences
of hexadecimal digits. Once you have typed four digits, the sequence will be
converted to a Unicode character automatically!
Now you can toggle between normal English input and Chinese input by
pressing the left ALT key plus the shift key. (You can also configure this
to CTRL-Shift instead.) There's an indicator for the current input language
in the taskbar. Once you're in Chinese mode, simply start entering sequences
of hexadecimal digits. Once you have typed four digits, the sequence will be
converted to a Unicode character automatically!
If you happen to know a foreign language, you can of course also install its language-specific IME and use it to enter characters in that language. The Japanese IME is one of the more complex examples for this. Japanese knows several character scripts:
| |
| © 2024 Parametric
Technology GmbH (a subsidiary of PTC Inc.), All Rights Reserved |