Zusammenfassung der Toleranzstapel
In der Tabelle Zusammenfassung der 1D-Toleranzstapel (Summary of 1D Tolerance Stackups) sind alle Stapel aufgeführt.
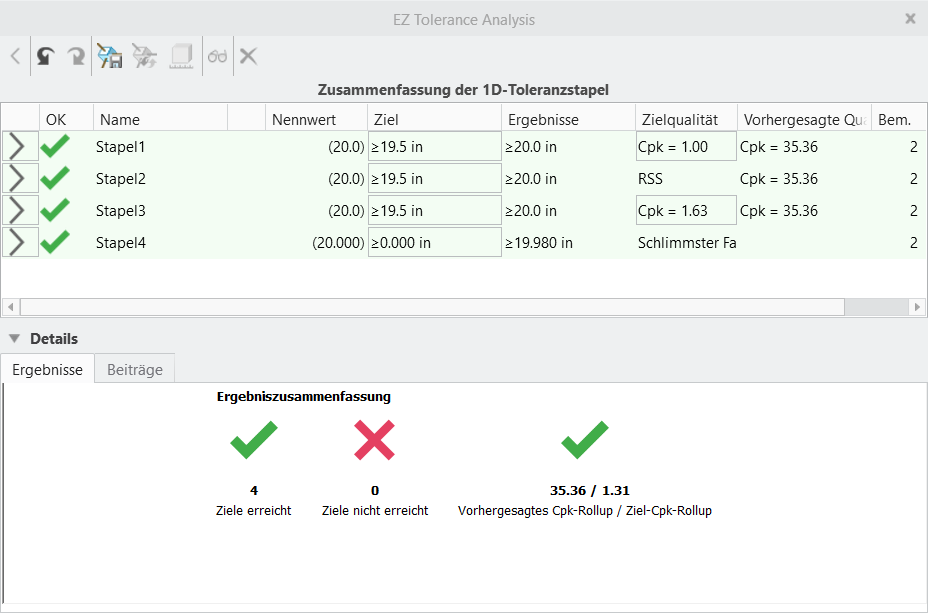
Es folgt eine Beschreibung der Tabellenspalten:
•  – Details eines Stapels. Klicken Sie auf , um die Tabelle mit Stapel-Details zu öffnen.
– Details eines Stapels. Klicken Sie auf , um die Tabelle mit Stapel-Details zu öffnen.
– Details eines Stapels. Klicken Sie auf , um die Tabelle mit Stapel-Details zu öffnen.• OK (OK) – Gibt an, ob ein Stapelergebnis die definierten Ziele erfüllt.
◦  – Ziele wurden verifiziert.
– Ziele wurden verifiziert.
– Ziele wurden verifiziert.◦  – Ziele wurden nicht erreicht.
– Ziele wurden nicht erreicht.
– Ziele wurden nicht erreicht.• Name (Name) – Name des Stapels im Format "Stapel <Nummer>" bei seiner Erzeugung. Die <Nummer> wird für jeden neu definierten Stapel fortlaufend angehängt. Sie können auf einen Stapel doppelklicken und einen eindeutigen Namen eingeben.
• Nennwert (Nominal) – Nominaler Abstand zwischen den ausgewählten Elementen, für die Sie die Stapelanalyse definieren möchten. Wenn Sie symmetrische ±- oder eindeutige +/--Werte verwenden, um die oberen und unteren Grenzwerte des Ziels relativ zum Nennwert zu definieren, wird der Nennwert ohne Klammern angezeigt. In diesem Fall ist der Nennwert Teil der Zieldefinition. Für die anderen Toleranztypen, die im nächsten Aufzählungspunkt beschrieben werden, wird der Nennwert als Referenz eingeschlossen und daher in Klammern angezeigt.
• Ziel (Objective) – Typ und Wert eines Toleranzziels. Klicken Sie auf den Wert, um das Dialogfenster Toleranz editieren (Edit Tolerance) zu öffnen. Sie können einen anderen Toleranztyp auswählen, um die oberen und unteren Ziele des Stapels zu definieren. Da die meisten Toleranzstapel definiert werden, um einen Abstand für die Einpassung sicherzustellen, ist der Standard-Zielwert für alle neuen Stapel ≥ 0.
Folgende Typen werden unterstützt:
◦ ± (symmetrisch) – bilateraler Wert, der relativ zum Nennwert angewendet wird.
◦ +/- (plus-minus) – nicht symmetrische Werte, die relativ zum Nennwert angewendet werden. Die Definitionen +/+ und -/- werden unterstützt.
◦ Grenzwerte (Limits) – Definition der absoluten oberen und unteren Grenzwerte für das Ziel, unabhängig vom Nennwert.
◦ ≤ (oberer Grenzwert) – Definition eines einzelnen oberen Grenzwerts.
◦ ≥ (unterer Grenzwert) – Definition eines einzelnen unteren Grenzwerts.
• In den angegebenen Zielwerten bestimmt die Anzahl der Nachkommastellen die zu verwendende Genauigkeit. Wenn Sie jedoch einen Wert ohne Dezimalstellen angeben, wird die Genauigkeit nicht geändert. • Das Vorzeichen und der Wert der angegebenen Zahl werden ausgewertet, um zu ermitteln, ob sie im oberen oder unteren Segment der Zieltypen +/- und "Grenzwerte" (Limits) platziert werden müssen. Wenn Sie kein Vorzeichen angeben, gilt das für das Feld ausgewiesene vorhandene Vorzeichen. |
• Ergebnisse (Results) – Ergebnisse der Stapelanalyse basierend auf dem definierten Zielqualitätsgrad. Die Ergebnisse werden im gleichen Toleranztyp dargestellt, der für die Zieldefinition verwendet wird, z.B. ±, +/- oder "Grenzwerte" (Limits).
• Zielqualität (Target Quality) – Typ der auszuführenden Analyse. Wählen Sie den Stapel aus, und wählen Sie dann in der Liste Analysetyp (Analysis type) eine Zielqualität aus.
◦ Schlimmster Fall (Worst Case) – Es wird angenommen, dass alle Bemaßungen gleichzeitig an den extremen zulässigen Grenzwerten liegen. Dies ist erforderlich, um den analysierten Stapelabstand zu minimieren oder zu maximieren.
◦ RSS (RSS) – Root Sum Square (RSS) ist eine statistische Methode zur Berechnung der Kombination von Bemaßungen basierend auf der Annahme, dass nicht alle am Stapel beteiligten Bemaßungen gleichzeitig an ihren Grenzwerten liegen. Der Hauptunterschied zwischen diesem Ansatz und dem allgemeineren statistischen Ansatz besteht darin, dass bei der RSS-Methode davon ausgegangen wird, dass jede der beitragenden Bemaßungen den gleichen Qualitätsgrad wie das berechnete Ergebnis hat. Die Baugruppenverschiebungen, die sich aus Abständen zwischen Teilen und aus Materialmodifikatoren ergeben, die auf die Bezugs-KEs in einem Referenzbezugssystem angewendet werden, werden als Worst-Case-Effekte betrachtet, z.B. die Baugruppenverschiebungen zum einen Extrem oder dem anderen, bevor die RSS-Kombination der beteiligten Toleranzen berechnet wird.
◦ Statistisch (Statistical) – Der statistische Ansatz basiert auf denselben Prinzipien wie die RSS-Analyse und bietet den Vorteil, dass Sie den Zielqualitätsgrad für den Stapel unabhängig von Annahmen definieren können, die für die Teilebemaßungen getroffen wurden. Er betrachtet außerdem die Abstände, die Baugruppen- und Bezugsverschiebungen zugeordnet sind, als statistische Beiträge mit einer gleichmäßigen Verteilung. Sie können die folgenden Metriken verwenden, um den Zielqualitätsgrad für statistische Analysen zu definieren:
▪ Cpk
▪ Σ (Sigma) – Unterscheidet sich von Kleinbuchstaben σ, der die Standardabweichung einer Normalverteilung darstellt.
▪ Prozent erzielt (%Yield)
▪ DPMO (Defects per Million Opportunities, Fehler pro Million Möglichkeiten)
Sie können die Standard-Zielqualität und die Standardwerte für die verschiedenen Qualitätsmetriken im Dialogfenster Optionen (Options) definieren. Klicken Sie auf > , um das Dialogfenster Optionen (Options) zu öffnen. |
• Vorhergesagte Qualität (Predicted Quality) – Berechnete Qualität der Stapelverteilung im Vergleich zum definierten Ziel, wenn die Zielqualität auf eine der statistischen Methoden festgelegt ist. Für RSS (RSS) beispielsweise wird die Beschriftung Cpk (Cpk) angezeigt. Für die allgemeinen statistischen Analysen wird als Beschriftung der für die Zielqualität definierte metrische Typ angezeigt.
• Anz. Bem. (#Dims) – Anzahl der Bemaßungen, die zu einem Stapel beitragen. Auf diese Weise können Sie bestimmen, ob Schlimmster Fall (Worst Case) oder eine der statistischen Optionen für die Zielqualität verwendet werden soll.
• Löschen (Delete) – Löscht die Stapeldefinition aus der Tabelle. Klicken Sie auf  , um die Stapeldefinition wiederherzustellen.
, um die Stapeldefinition wiederherzustellen.
, um die Stapeldefinition wiederherzustellen.