计算字段
本主题介绍有关计算字段的概念,并深入说明如何使用此类字段以及Codebeamer 中提供的函数。
跟踪器字段可以定义为只读的计算字段,其中的内容通过其他跟踪器项字段进行计算。可通过统一的表达式语言指定表达式或公式来创建计算字段。

某些内置字段 (例如 Summary、ID、Parent、Description、Status、Submitted on/at 和 Submitted by) 不能定义为计算字段。“计算为”部分不适用于这些字段。 |
要处理计算字段,Codebeamer 必须确保底层跟踪器项特性和数据库中的历史或新字段值均为最新,这意味着将在数据库中对其进行重新计算和更新。
在“计算为”字段中添加或更改公式,或者直接或间接更改任何计算参数时,计算过程可能需要很长时间。在此类用例中,Codebeamer 会显示以下消息:“已计算的字段正在此跟踪器中重新计算,因此其值可能会过时并将很快更新...”。
删除跟踪器并不会触发任何计算字段。 |
管理员的应用程序配置
Codebeamer 管理员可以使用“应用程序配置”来配置计算字段的行为。有关详情,请参阅 "computed-update" 应用程序配置。有关语言表达式的技术和开发相关信息,请参阅关于计算字段中表达式语言的技术详情。
用例
用例 1:用于解决事项的过去最后期限测试
本用例旨在显示项是否已过排定的结束日期。在跟踪器中,单击  > > > 。
> > > 。
> > > 。对于 Codebeamer 中的项,过去的结束日期以红色感叹号表示。 |
自定义字段名称为 Past Deadline,您必须将其设置为布尔类型。如果项的结束日期非常晚,该字段会返回 true。在字段的“布局和内容”列下,对于自定义字段,= 字段的定义如下:
not(endDate >= fn:Date("today"))
选中“字段”选项卡上 List 列中的复选框,以在项列表或详情页面中显示自定义字段。必须在“权限”选项卡上设置权限。计算字段始终为只读字段;只有在删除字段定义且该字段变为非计算字段的情况下,才可以拥有该字段的写入权限。如需详细了解可用于已计算的跟踪器字段的函数,请参阅函数。
用例 2:Weight = Priority * Severity
目标是使用以下表达式,将事项优先级和严重性合并到新的 Weight 字段中:
Weight = Priority * Severity
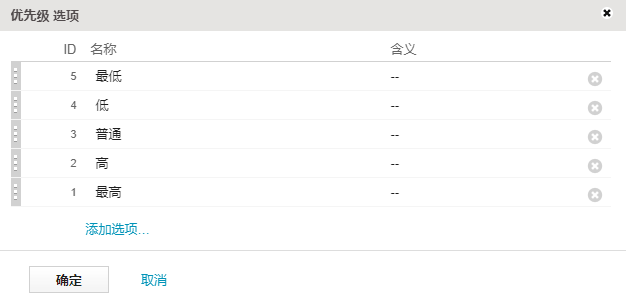
Priority 是具有以下选择值的单选字段:
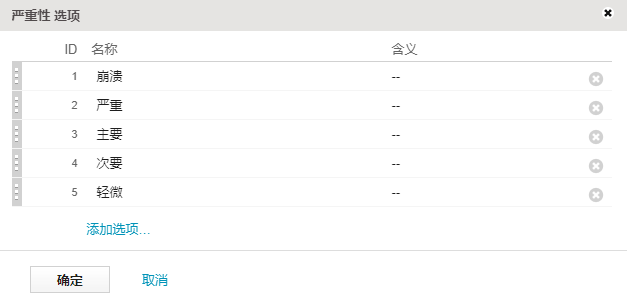
Severity 是具有以下定义值的多选字段:
除了 Status 和 Priority 之外,其他所有选择字段均为值列表或值数组。但是,静态选择字段的用户界面当前仅允许选择单个值。因此,要访问多选字段的第一个值或单个值,必须使用 [0] 运算符。例如,Severity[0]。 |
所选的最高优先级和最高严重性 (Blocker) 具有最低的 ID。因此,要计算与 Priority 和 Severity 的逻辑阶数成正比的 Weight,必须使用与选择值 ID 成反比的操作数。
示例:
integer Weight = (5 - Priority.id) * (6 - Severity[0].id)
如果 Priority 或 Severity 为空,由此得到的 ID 为 null,上述公式将针对 Priority 和 Severity 为空的事项,返回可能的最高权重 = 30。为了避免这种错误的结果,必须妥善处理空值。
示例:
integer Weight = (empty Priority ? 0 : 5 - Priority.id) * (empty Severity ? 0 : 6 - Severity[0].id)
用例 3:从其他列的值计算嵌入式表格中的列
跟踪器项可以包含表格。表格由一列或多列组成,如下所示:
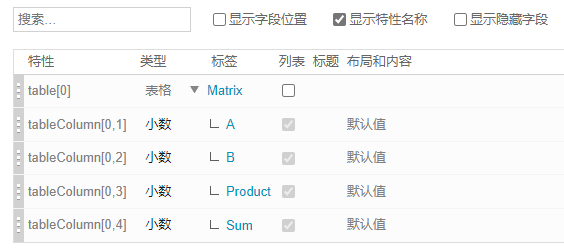
前两列 A 和 B 包含数字操作数,而其他两列必须包含每行操作数的乘积及总和或总数。
例如,按表列的属性或特性名称 tableColumn[0,1] 对表列进行寻址时,始终对整列进行寻址以生成按行建立索引的列值的数组或向量。
关于 Matrix 表的示例:
A | B |
|---|---|
1 | 5 |
2 | 6 |
3 | 7 |
对表达式 A 或 tableColumn[0,0] 进行求值,得到 [1, 2, 3] 和 B;或对 tableColumn[0,1] 进行求值,得到 [5, 6, 7]。
要对整个表进行寻址,请使用该表的名称或属性,例如 Matrix 或 table[0],由此得到一个表行数组,其中每一行都是一个按列顺序排列的表列值数组。
[
[1, 5],
[2, 6],
[3, 7]
]
[1, 5],
[2, 6],
[3, 7]
]
第一行的索引为 0,第一个表行可通过下列其中一种方式进行访问:
• table[0][0]
• Matrix[0]
由此得到 [1, 5]。
要对矩阵第二行中列 A (tableColumn[0,0]) 的值进行寻址,请写入:
• table[0][1][0]
• Matrix[1][0]
• tableColumn[0,0][1]
• A[1]
我们定义第三列 Product,其值为每行的 A 与 B 的乘积,方式如下:
如果 Product 的计算公式定义如下:
• tableColumn[0,0] * tableColumn[0,1]
• 或简写为 A * B
那么,这表示两个向量的乘积,例如 [1, 2, 3] * [5, 6, 7],而表达式语言并不支持此运算。
此外,结果为二维数组而非一维列值向量。
解决方案是使用投影 table.{ row | expression},该投影会遍历 table 中的每个 row,并生成一个值数组,根据 expression,一个值对应一个 row。

投影或表达式如下:
table[0].{row | row[0] * row[1] }
可以将其理解为:
• 遍历 table[0]
◦ 对于每个 row (列值数组)。对表达式 row[0] * row[1] 求值
• 针对每行返回表达式值的数组。
例如,在表格中,结果为数组或向量:[5, 12, 21]
tableColumn[x,y] 是固定的特性名称文本,在更改列位置时不会调整 y。如果定义的公式中包含表列,在这种情况下,不要依赖列的顺序,而是要检查特性名称。要执行此操作,可以在字段配置对话框中选中“显示特性名称”复选框。 在其他位置,[y] 用作索引号而不是文本。例如,table[x][y] 是指 table[x] 中的第 y 行。 |
Codebeamer 变更
Codebeamer 中已对表列索引的解释进行更改,这可能会破坏在较旧版本中编写的表达式。 |
在 Codebeamer 的较早版本中,列索引被解释为表列列表中列的序数索引。因此,如果添加或移除列,或者对列进行重新排序,可能会更改列的序数索引。
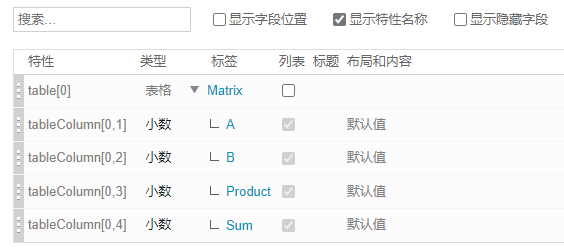
Product 的序数索引原来为 2,现在为 3,这会导致通过表列索引访问的表格单元格不一致:table[0][row][3]
!= tableColumn[0,2][row]
在 Codebeamer 中,列索引始终被解释为不可变且唯一的列 ID,这是不可变且唯一的列特性名称中的第二个索引。
例如,Product (tableColumn[0,2]) 的列 ID 或索引为 2,与其位置无关。添加或移除列,或者对列进行重新排序,这并不会更改现有列的列 ID 或索引,并且列访问保持一致:table[0][row][2]==tableColumn[0,2][row]