データ難読化ツール
Codebeamer 3.0 以降、新しいデータ難読化ツールを使用できます。このツールを使用すると、ユーザーは機密情報を共有することなく、ほかのチームとデータを共有できます。このツールは、Codebeamer 2.0、2.1、2.2、および 3.0 でサポートされています。
以前のソリューションでは、シングルスレッドの SQL スクリプトが使用されており、低速でした。新しいツールは Java アプリケーションであり、効率性が向上しています。また、難読化されたデータのエクスポートや、ターゲットデータベースにデータをインポートするためのツールキットの提供など、新機能が導入されています。このツールは複数のデータベースタイプをサポートしており、大幅なパフォーマンスの向上を実現しています。コンフィギュレーションは柔軟性を備えており、マルチスレッド処理やコンテナ化された配布が可能です。そのため、Jenkins パイプラインでの使用に適しています。このツールは一般的なデータベースタイプをサポートしており、Postgres 用の SQL ファイルと、Oracle および MySQL 用の CTL ファイルを生成します。また、インポートプロセスを合理化するための bash スクリプトも提供しており、データ難読化のためのエンドツーエンドソリューションとなっています。
|
|
Codebeamer は、Codebeamer 2.0 および 2.1 バージョンでのみ MySQL をサポートしています。
|
新しい難読化ツールは、次の 3 つのステップのプロセスで動作します。
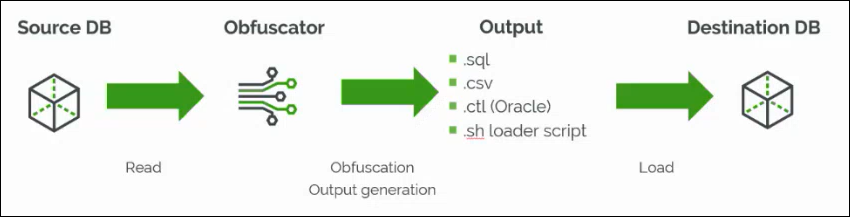
1. コンフィギュレーションに基づいて、ソースデータベースからデータを抽出する。
2. データを匿名化し、難読化されたデータを含む .CSV ファイルを生成する。
3. インポートおよびシーケンスの設定ファイルを作成する。
難読化の範囲
ユーザーテーブルでは、ログインに必要な名前と電子メールを除き、すべてのフィールドがクリアされます。タスクテーブルでは、サマリーフィールドは難読化され、説明フィールドは短縮されます。ユーザープリファレンステーブルでは、condition コラムに応じて、データはロードされずに削除されます。新しいツールでは、従来の SQL スクリプトと同じ機能を維持しながら、パフォーマンスが向上しています。
難読化ツールは、さまざまなデータ型を異なる方法で処理します。名前、電子メール、ユーザー名などのコラムを含むユーザーテーブルの場合、一般的なデータタイプは次の方法で管理されます。
• 名前
◦ 置換: 名前は、匿名性を確保するために、ランダムに生成された、または事前定義された偽名に置き換えられます。
◦ パターンマッチング: 正規表現またはその他のアルゴリズムを使用して、名前フィールドを一貫した方法で識別および置換します。
• 電子メール
◦ 匿名化: 電子メールアドレスは、ローカル部分 (@ 記号の前) をランダムな文字や偽名に置き換え、ドメイン部分をそのまま保持するか、または一般的なドメインを使用することで難読化されます。
◦ 一貫性: 異なるテーブル間で、同じ電子メールアドレスが一貫して同じ仮名に置き換えられるようにします。
• ユーザー名
◦ 正規表現: ユーザー名は、正規表現を使用して照合され、匿名化されたバージョンに置き換えられます。
◦ 一意の識別子: ユーザー名を置き換える一意の識別子を生成し、重複が発生しないようにします。
• その他のフィールド
◦ カスタム規則: 住所、電話番号、その他の機密情報などのフィールドに対して、フォーマットと構造を維持しながらデータを置換または匿名化するためのカスタム規則およびアルゴリズムが適用されます。
◦ 切り捨て: 説明やサマリーなどのフィールドに対して、このツールは、データを使用可能な状態で維持しながら、機密情報を除去するためにテキストを切り捨てる場合があります。
次の表は、データの難読化の範囲を示しています。
table {mso-displayed-decimal-separator:"\."; mso-displayed-thousand-separator:"\,";} tr {mso-height-source:auto;} col {mso-width-source:auto;} td {padding-top:1px; padding-right:1px; padding-left:1px; mso-ignore:padding; color:black; font-size:11.0pt; font-weight:400; font-style:normal; text-decoration:none; font-family:"Aptos Narrow", sans-serif; mso-font-charset:0; text-align:general; vertical-align:bottom; border:none; white-space:nowrap; mso-rotate:0;} .xl17 {color:#242424; font-family:"Aptos Narrow"; mso-generic-font-family:auto; mso-font-charset:1;} .xl18 {color:#467886; text-decoration:underline; text-underline-style:single;} .xl19 {white-space:normal;}
テーブル | コラム | 難読化後 |
|---|---|---|
acl_role | description | null |
acl_role | name | id |
audit_trail_logs | details | name: user-{id}'s Personal Wiki |
audit_trail_logs | details | {key}: {name: {key}-{id}, id:{id} |
audit_trail_logs | details | user-{id} [id] |
audit_trail_logs | details | user-{id} or user-{id} [id] |
existing | name | Project{project_id} |
existing | key_name | K-{project_id} |
label | name | LABEL{id} |
object_reference | url | USER-{id} |
object_reference | url | https://obfuscator.ptc.com |
object_reference | url | file://{from_id} |
object_reference | url | /{from_id} |
object_reference | url | mailto:{from_id}@testemail.testemail |
object_revision | description | category フィールドは 'TestCategory' に置き換えられ、keyName フィールドは K-{proj_id} に置き換えられます。 |
object_revision | description | categoryName フィールドは、name コラムの値に置き換えられます。 |
object_revision | description | Null |
object_revision | description | JSON 内の description フィールドは、Obfuscated description - {length(description field)-{type_id}} に置き換えられます。 |
object_revision | description | Obfuscated description - {length(description)} |
object_revision | name | {object_id}-artifact {substring(name,4)}:{length(name)} |
simple_field_value | value | 15 文字のランダムな英数字 - {length(field_value}-{id} |
simple_large_field_value | large_field_text | 15 文字のランダムな英数字 - {length(field_value}-{id} |
simple_plain_text_field_value | plain_text | substring(field_value,100) を取得し、数値と - をスペース文字に置き換え、結果が空の文字列の場合はトリムします。この場合、難読化された値は 1 になります。それ以外の場合は、substring(field_value,2) :length(field_value) になります。 |
task_type | prefix | substring(prefix, 2) |
users_small_photo_blobs | blob_data | 小さな置換イメージ |
users_large_photo_blobs | blob_data | 小さな置換イメージ |
user_pref | pref_id | Null |
user_pref | user_id | Null |
user_pref | pref_value | Null |
users | email | user{id}@testemail.testemail |
users | firstname | First-{id} |
users | lastname | Last-{id} |
users | name | user-{id} |
users | -> | Null |
workingset | description | Null |
workingset | name | WS-{id} |
user_key |
object_job_schedule |
object_revision_blobs |
object_quartz_schedule |
application_configuration |
document_cache |
document_cache_data |
background_job |
background_job_meta |
background_job_step |
background_job_step_context |
background_job_step_result |
export_job_report |
monitoring_log |
field_value_search_history |
history_search_update |
object_tag |
reference_search_history |
task |
task_field_history |
task_field_value |
task_reference_tag |
task_revision |
task_search_history |
task_tag |
テーブル | コラム | 難読化後 |
|---|---|---|
acl_role | description | null |
acl_role | name | id |
audit_trail_logs | details | name: user-{id}'s Personal Wiki |
audit_trail_logs | details | {key}: {name: {key}-{id}, id:{id} |
audit_trail_logs | details | user-{id} [id] |
audit_trail_logs | details | user-{id} or user-{id} [id] |
existing | name | Project{project_id} |
existing | key_name | K-{project_id} |
label | name | LABEL{id} |
object_reference | url | USER-{id} |
object_reference | url | https://obfuscator.ptc.com |
object_reference | url | file://{from_id} |
object_reference | url | /{from_id} |
object_reference | url | mailto:{from_id}@testemail.testemail |
object_revision | description | category フィールドは TestCategory に置き換えられ、keyName フィールドは K-{proj_id} に置き換えられます。 |
object_revision | description | categoryName フィールドは、name コラムの値に置き換えられます。 |
object_revision | description | null |
object_revision | description | JSON 内の description フィールドは、Obfuscated description - {length(description field)-{type_id}} に置き換えられます。 |
object_revision | description | Obfuscated description - {length(description)} |
object_revision | name | {object_id}-artifact {substring(name,4)}:{length(name)} |
task | details | Task details obfuscated - {substring(details, 4)} : {length(details)} |
task | summary | Task summary obfuscated - {substring(summary, 4)} : {length(summary)} |
task_search_history | summary | Task summary obfuscated - {substring(summary, 4)} : {length(summary)} |
task_field_history | old_value | 15 random alphanumeric characters-{length(old_value}-{task_id}-{{revision}-1} |
task_field_history | new_value | 15 random alphanumeric characters-{length(new_value}-{task_id}-{label_id}-{revison} |
task_field_value | field_value | 15 random alphanumeric characters-{length(field_value}-{task_id}-{label_id} |
task_type | prefix | substring(prefix, 2) |
users_small_photo_blobs | blob_data | 小さな置換イメージ |
users_large_photo_blobs | blob_data | 小さな置換イメージ |
user_pref | pref_id | Null |
user_pref | user_id | Null |
user_pref | pref_value | Null |
users | email | user{id}@testemail.testemail |
users | firstname | First-{id} |
users | lastname | Last-{id} |
users | name | user-{id} |
users | -> | null |
workingset | description | null |
workingset | name | WS-{id} |
user_key |
object_job_schedule |
object_revision_blobs |
object_quartz_schedule |
application_configuration |
document_cache |
document_cache_data |
background_job |
background_job_meta |
background_job_step |
background_job_step_context |
background_job_step_result |
export_job_report |
monitoring_log |
audit_trail_logs では、ユーザー名およびその他の名前フィールドが変更されます。難読化ツールは、さまざまなテーブルでさまざまなタイプのデータを変更します。
• ユーザー名の難読化: 監査証跡ログ内のユーザー名は、ユーザーのプライバシーを保護するために匿名化されたバージョンに置き換えられます。
• イベント詳細の保持: ログの整合性を維持するために、成果物名やイベントタイプなど、監査証跡ログ内のその他の重要な詳細は保持されます。
• JSON フォーマットの処理: このツールは、監査証跡ログ内の JSON フォーマットのデータを処理します。これにより、ログの全体的な構造と使いやすさを保持しながら、機密情報を難読化できます。
パフォーマンスの向上
• 正規表現の置き換え: ソースデータベースからデータを取得した後のデータ処理を高速化するために、このツールでは、正規表現の代わりにより効率的なアルゴリズムが使用されるようになりました。
• 小さなデータセットへのテーブルの分割: 大きなテーブルをより小さく、管理しやすいデータセットに分割することで、ツールはデータを並列に処理できます。
• マルチスレッドの導入: このツールは、複数のスレッドを使用してデータの異なる部分を同時に処理することで、難読化プロセスを大幅に高速化します。
難読化ツールのコンフィギュレーション
難読化ツールのコンフィギュレーションでは、次のパラメータを指定します。
• 出力場所を示すのは、コンフィギュレーションファイルでは exportDirectory です。
• ソースデータベースの接続プロパティは、コンフィギュレーションファイルでは src.JDBC.Driver、src.JDBC.ConnectionURL、src.username、および src.password です。
Oracle データベースの難読化では、接続 URL のデータベーススキーマが Codebeamer テーブルのオーナーと一致している必要があります。一致していない場合、ツールはテーブルを検出できません。 |
• 進捗状況レポートのプロパティ
◦ collectStatistics: テーブルデータセット内のテーブルごとに現在の進捗状況についてより詳細な統計を収集するかどうかを指定。true に設定すると、実行時間が長くなる場合があります。これは、テーブルを複数のセクションに分割するために必要です。
◦ refreshInterval: 進捗状況情報を再表示する時間間隔。これは秒単位で指定します。
• 作業スレッドの数
◦ WorkerThreads: アプリケーションに使用可能なスレッドの数であり、テーブル内の並列処理に使用可能なスレッドの数。
◦ TableParallel: 1 つのテーブルで同時に使用できるスレッドの最大数。
◦ totalSections: テーブルの最大分割数。これは、collectStatistics が true に設定されている場合に影響を受けます。
• 読み取りバッチサイズを示すのは、コンフィギュレーションファイルでは fetchSize です。
入力コンフィギュレーションファイルの例を以下に示します。
# EXPORT LOCATION IN THE FILE SYSTEM:
# UNIX DEFAULT
exportDirectory=/tmp/obfuscator/export
# WINDOWS EXAMPLE
#exportDirectory=C:\\tmp\\obfuscator\\export
# DATABASE CONFIG:
# POSTGRESQL DEFAULT
src.JDBC.Driver=org.postgresql.Driver
src.JDBC.ConnectionURL=jdbc:postgresql://localhost:5432/cb_example
src.username=cbuser
src.password=cbpassword
# ORACLE EXAMPLE
#src.JDBC.Driver=oracle.jdbc.driver.OracleDriver
#src.JDBC.ConnectionURL=jdbc:oracle:thin:@//172.21.0.2:1521/ORCLCDB
#src.username=cbuser
#src.password=cbpassword
collectStatistics=true
# OPTIONAL CONFIGS:
refreshInterval=120
workerThreads=15
tableParallel=5
fetchSize=1000
totalSections=10
# UNIX DEFAULT
exportDirectory=/tmp/obfuscator/export
# WINDOWS EXAMPLE
#exportDirectory=C:\\tmp\\obfuscator\\export
# DATABASE CONFIG:
# POSTGRESQL DEFAULT
src.JDBC.Driver=org.postgresql.Driver
src.JDBC.ConnectionURL=jdbc:postgresql://localhost:5432/cb_example
src.username=cbuser
src.password=cbpassword
# ORACLE EXAMPLE
#src.JDBC.Driver=oracle.jdbc.driver.OracleDriver
#src.JDBC.ConnectionURL=jdbc:oracle:thin:@//172.21.0.2:1521/ORCLCDB
#src.username=cbuser
#src.password=cbpassword
collectStatistics=true
# OPTIONAL CONFIGS:
refreshInterval=120
workerThreads=15
tableParallel=5
fetchSize=1000
totalSections=10
難読化プロセス
このツールはコンテナで実行するように設計されており、Jenkins パイプラインと統合することでビルドと実行を自動化できます。パイプラインでは、GitHub からツールのソースコードをダウンロードして JAR ファイルをビルドすることもできます。Codebeamer のダウンロードページから JAR ファイルをダウンロードします。
必要条件
◦ Codebeamer 2.0 から 2.1 の場合、Java 17 がホストにインストールされている必要があります。
◦ Codebeamer 2.2 以降では、Java 21 が ホストにインストールされている必要があります。
データ難読化の手順は次のとおりです。
1. データベースの準備
基本データを含むソースデータベースと、スキーマのみを含む宛先データベースを設定します。
a. jar ファイルの場所に移動します。
b. config.properties を設定します。
c. 正しい引数を追加した後、次のコマンドを実行します。
java -XX:+ExitOnOutOfMemoryError -jar <JAR file name> <Config file location and name>
例: java -XX:+ExitOnOutOfMemoryError -jar 3.0-obfuscator.jar config.properties
2. 難読化ツールの実行
準備した jar ファイルとコンフィギュレーションファイルを使用します。
ツールを起動すると、テーブル情報が読み取られ、大きなテーブルが小さなデータセットに分割されます。
3. 進捗状況の監視
このツールには、読み取りおよび処理された行数など、進捗状況が表示されます。
4. 出力ファイルの生成
このツールは、指定したエクスポートディレクトリ内に出力ファイルとロードスクリプトを作成します。
実行が完了すると、exportDirectory には、エクスポートされたデータが、.csv ファイルと、data_load_and_sequence_setup.sql または data_load_and_sequence_setup.ctl という名前の SQL ファイルに格納されます。これは、空のデータベーススキーマを持つターゲットインスタンスで実行できるロードスクリプトです。
5. 難読化されたデータの確認
生成されたファイルをチェックして、名前やその他の機密情報などの難読化されたデータを確認します。
6. 宛先データベースへのデータのロード
生成された SQL スクリプトと bash スクリプトを使用して、難読化されたデータを宛先データベースにロードします。
このツールは、並列処理を使用してデータを効率的にロードします。
シーケンス設定スクリプトを実行してデータベースの設定を完了します。
7. データの検証
宛先データベースをチェックして、データが正しくロードされ、期待どおりに難読化されていることを確認します。
Jenkins による自動化
プロセスを Jenkins パイプラインに統合して、ビルドと実行を自動化します。
関連するすべての設定の処理と難読化ツールの実行が手動操作なしで行われるように、Jenkins を設定します。