ThingWorx 高可用性
ThingWorx 高可用性的概觀
欲減少重要物聯網 (IoT) 系統中斷的持續時間,您可以將 ThingWorx 配置為在高可用性 (HA) 環境中運作。本指南將討論有關 ThingWorx 系統以及構成 ThingWorx HA 部署之元件所需的 HA 考量。
相較於僅符合功能和規模需求的部署,所有 HA 部署都需要額外的資源。這些包括以硬體為基礎的 (例如伺服器、磁碟、負載平衡器,等等) 與以軟體基礎的 (例如同步處理服務及負載平衡器) 附加資源。因此,配置附加資源以確保 HA 部署內沒有單一點失敗。
所有 HA 部署應該將已針對部署分析了應用程式執行時間需求的 SLA (服務層級合約) 作為基礎。例如,系統每個月可以處於離線狀態的小時數?這是否為允許的系統失敗與/或應用程式升級停機時間?HA 系統所需的其他資源數目取決於為其設計的目標 SLA。一般而言,SLA 增加,滿足其需求的資源也會隨之增加。
定義
• 高可用性
將依預期持續運作很長一段時間的系統或元件。
• 主動/主動
可以同時作用的相同應用程式的實例。
• 主動/被動
可作用一次的應用程式實例。也可使用其他實例,並且可以視需要取代服務。
• 前置節點或主要伺服器
主動/被動 HA 組態中的主動伺服器,其中所有流量都已路由。
• 待命
主動/被動 HA 組態中等待目前前置節點失敗時接管服務的伺服器。
• 虛擬 IP 位址
表示應用程式的 IP 位址。使用虛擬 IP 的用戶端通常路由到負載平衡器,然後由該負載平衡器將請求導向至執行應用程式的伺服器。
• 負載平衡器
此裝置用於接收網路流量並將其散發至準備好接受該網路流量的應用程式。對於主動/被動 HA 組態,負載平衡器將流量導向至目前的前置節點。對於主動/主動 HA 組態,負載平衡器將流量導向至許多應用程式中的一個應用程式。
• 容錯移轉
此為備份操作模式,在主要元件因為失敗或計劃停機時間而無法使用時,系統元件 (例如處理器、伺服器、網路或資料庫) 的功能將由次要系統元件承擔。
高可用性 ThingWorx 參考架構
下圖顯示了高可用性組態的 ThingWorx。
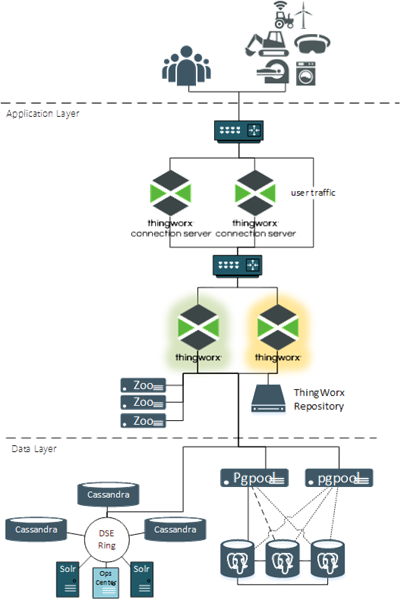
以下是此組態中的元件及其在 HA 部署中的角色:
• 使用者和裝置 - HA 功能中沒有角色。從其角度來看未發生任何變更。即使主要 ThingWorx 伺服器中發生了變更,它們始終使用相同的 URL 和 IP 位址。
• 防火牆 - 無 HA 功能,並可視為選用。通常放置防火牆來實現安全性需求。
• 負載平衡器 - 負載平衡器管理其支援的應用程式的虛擬 IP 位址。路由至虛擬 IP 位址的所有流量都將被導向至可接收此流量的使用中應用程式。
• ThingWorx Connection Servers - 接收源自資產的 Web 通訊端流量並將其路由到 ThingWorx Platform。連線伺服器可在主動/主動組態中運作。資產被導向至特定的連線伺服器之後,它應該始終使用相同的連線伺服器。如果該伺服器變成離線狀態,則資產應被重新導向至其他可用的連線伺服器。
• ThingWorx Foundation - 接收所有使用者與資產流量。ThingWorx Foundation 在使用一個前置節點和一或多個待命伺服器的主動/被動組態中運作。前置節點在線且正在接收流量。應用程式正在執行,但沒有連線至資料庫的使用中連線且未收到流量時,待命伺服器將以暖機狀態執行。負載平衡器將所有流量都路由至前置節點。如果前置節點變成離線狀態,則待命伺服器將升級為前置節點,然後系統會將流量路由至此伺服器。
• ThingWorx 存放庫 - 這些是必要的儲存位置,例如 ThingworxPlatform、ThingworxStorage 與 ThingworxBackupStorage,以及任何新增以支援實行的其他儲存位置。針對 HA 環境,ThingWorx 存放庫必須存在於常用儲存位置,其中所有 ThingWorx 伺服器 (前置節點和待命伺服器) 對該位置有相同的存取權限。
• Apache ZooKeeper - ZooKeeper 是 ThingWorx 所使用的集中協調服務,可隨時選擇其中一個 ThingWorx 伺服器作為前置節點。ZooKeeper 用戶端內嵌在每個 ThingWorx 伺服器中,以維護活動訊號並回應組態中的變更,例如目前 ThingWorx 前置節點失敗。
• PostgreSQL - 對於 HA 組態,PostgreSQL 將透過熱待命組態中的兩個或多個伺服器節點進行運作。一個節點接收所有寫入流量,其他節點中的一個可以接收所有讀取流量。將啟動所有節點之間的串流複製,以使得每個節點保持最新。
• Pgpool-II - 這僅用於 PostgreSQL HA 組態。Pgpool-II 節點接收 ThingWorx 請求 (讀取與寫入) 並將其導向至適當的 PostgreSQL 節點。它也監視每個 PostgreSQL 節點的健康狀況,並可在其中一個節點離線時啟動容錯移轉及重定任務。
• Microsoft SQL Server (無圖片) - Microsoft 容錯移轉功能用來確保至少有一個 MS SQL Server 已上線而且可用。
• DataStax Enterprise (DSE) - ThingWorx HA 組態不需要 DSE 實行。如果需要其符合實行的擷取需求,則請確保針對 HA 配置此選項。一般 DSE 實行會符合大多數 HA 需求。它有多個 Cassandra 節點收集內容且至少位於兩個 Solr 節點上。DSE 設計至少將所有內容複製到其他節點中的一個。
安裝前的需求
注意與警告:
• 此 HA 流程中的步驟應供先前已有 HA 組態 (PostgreSQL、Microsoft SQL Server 和 DataStax Enterprise) 中關聯式資料庫經驗的資料庫管理員 (DBA) 使用。必要知識包括安裝、最佳化與高可用性叢集。
• 此處提供的指南適用於部署 HA 環境。生產環境中可能需要進行其他效能調整,但此處未提供。
• 詳細步驟為參考範例,僅適用於 QA 或沙箱環境。安裝程式可能需要在生產環境中編輯指令和設定以獲得最佳效能。
• 所有故障轉移組態在生產中使用之前必須進行全面測試與驗證。
• 此流程中的步驟不討論容錯回復情境,其中失敗的前置節點將被修正,然後返回到前置節點位置。它假設失敗的元件會進行修正並作為非前置節點元件返回到服務。
支援的作業系統
一般 HA 需求
虛擬 IP 位址
• 連線伺服器的使用者和資產 (如果使用了連線伺服器)
• ThingWorx Foundation 的連線伺服器
• PostgreSQL HA 的 ThingWorx Foundation (如果使用了 PostgreSQL)
• Microsoft SQL Server HA 的 ThingWorx Foundation (如果使用了 Microsoft SQL Server)
硬體需求
此處提供的步驟假設在 ThingWorx HA 組態中使用了完整的硬體冗余。
• 應用程式的每個實例應在單獨的硬體上執行以避免硬體層級出現單一失敗點。例如,ThingWorx 伺服器,無論是實體、虛擬亦或以雲端為基礎,都不應在相同的實體硬體上運作。
• ThingWorx HA 組態中的所有應用程式 (ThingWorx、PostgreSQL、DataStax Enterprise、ZooKeeper 等) 均應滿足此要求才能減輕硬體失敗的風險。
• 此處提供的流程假設存在多餘的路由器、交換器、電源供應器等。
HA 組態中的 ThingWorx 內容
應將 ThingWorx 內容設定為持續性內容以防止資料在發生容錯移轉時遺失。如果 ThingWorx 內容不是持續性內容,則從主要伺服器到次要伺服器的容錯移轉將會清除記憶體中的值。
PostgreSQL 需求
• Pgpool-II 與 PostgreSQL DB 已安裝在 RHEL 或 Ubuntu 環境中。
• 至少有兩個資料庫主機伺服器執行受支援的 PostgreSQL 版本。建議使用三個。
• 通常是透過兩個伺服器執行配置了看門狗的 Pgpool-II 3.7.<最新>。以上是此處提供的一個範例,但也可選擇其他不使用 Pgpool-II 的 HA 組態選項。
Microsoft SQL Server 需求
• 至少有兩個資料庫主機伺服器執行受支援的 Microsoft SQL Server 版本。
• Microsoft SQL Server 已配置為透過下列 Microsoft HA 方法之一運作:
◦ AlwaysOn 容錯移轉叢集實例
◦ Always On 可用性群組
DataStax Enterprise 需求
• DataStax Enterprise 叢集至少有五個節點:
◦ 三個 Cassandra 節點
◦ 兩個 Solr 節點
◦ (選用) 一個用於管理工作的 DSE OpsCenter 節點,因為 OpsCenter 對於操作而言並不關鍵,也無需高可用性組態。
InfluxDB 需求
• 至少兩個中繼節點,對於大多數使用案例建議使用三個
• 至少兩個資料節點,建議使用偶數個資料節點
• 一般部署應有三個中繼節點和偶數個資料節點