说话者识别
“Azure 说话者识别”可用于标识说话者或使用语音对用户进行身份验证。有关详细信息,请参阅
Azure 说话者识别。
使用“说话者识别”操作可标识说话者或对说话者进行身份验证。
完成以下步骤可在工作流中使用“说话者识别”操作:
1. 将 Azure 下的“说话者识别”操作拖动至工作区,并将指针置于该操作上,然后单击  或双击该操作。
或双击该操作。
或双击该操作。“说话者识别”窗口随即打开。
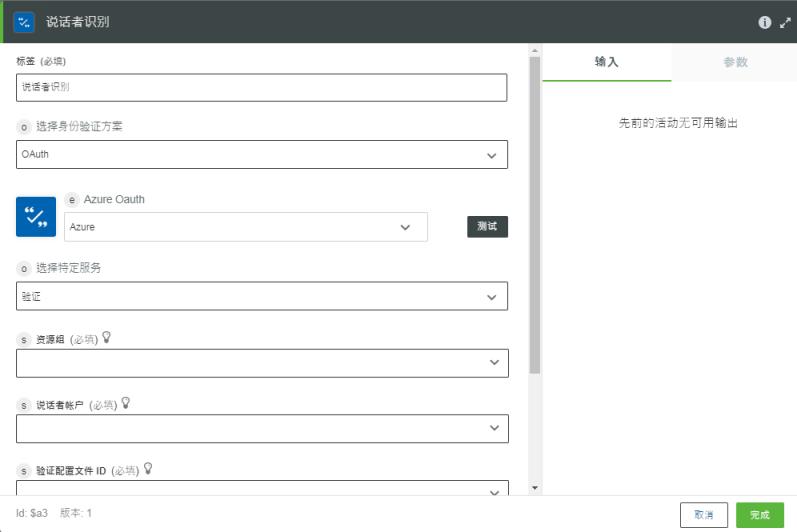
2. 根据需要编辑“标签”。默认情况下,标签名称与操作名称相同。
如果之前已为 Azure 添加了身份验证模式,请从列表中进行选择。
4. 在“选择特定服务”列表中,选择下列选项之一,然后执行以下操作:
◦ 选择“验证”并执行以下操作:
1. 在“资源组”列表中,选择在 Azure 订阅下定义的相应资源组。
2. 在“说话者帐户”列表中,选择合适的说话者识别帐户。
3. 在“验证配置文件 ID”列表中,从说话者识别帐户中选择配置文件 ID。
4. 在“音频文件”字段中,映射上一操作的输出以提供音频文件的路径。
◦ 选择“标识”并执行以下操作:
1. 在“资源组”列表中,选择在 Azure 订阅下定义的相应资源组。
2. 在“说话者帐户”列表中,选择合适的说话者识别帐户。
3. 在“音频文件”字段中,映射上一操作的输出以提供音频文件的路径。
4. 在“说话者”组下的“标识配置文件 ID”列表中,从说话者识别帐户中选择配置文件 ID。
单击“添加”可添加多个配置文件 ID。或者,单击  删除配置文件 ID。
删除配置文件 ID。
删除配置文件 ID。5. 单击“完成”。
输出架构
“说话者识别”操作的输出架构会返回包含置信度和短语的结果。
对于“验证”,“结果”为“接受”或“拒绝”,而“短语”为说话者所说的句子。
对于“标识”,“结果”为人员的 ID。如果说话者识别 API 在配置文件 ID 中未找到匹配项,则会返回一个空值作为“结果”。对于“短语”字段,该操作会返回一个空值。
下图显示了示例输出架构:
