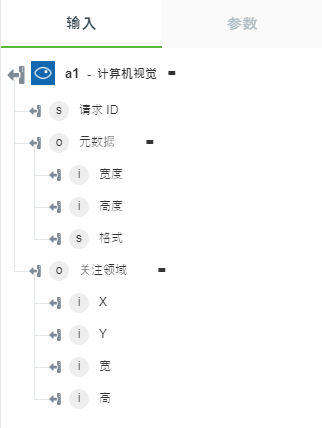
计算机视觉
Azure 计算机视觉可为开发人员提供处理图像和返回信息的高级算法。要分析图像,您可以上载图像或指定图像 URL。处理算法可根据不同的视觉特征以不同方式分析图像的内容。例如,利用“计算机视觉”可以找出图像中的所有人脸。有关详细信息,请参阅
Azure 计算机视觉。
使用“计算机视觉”操作可分析图像、按领域分析图像、描述图像以及检测图像的视觉特征和特性并提供相关见解。
请确保您的图像满足以下要求:
• JPEG、PNG、GIF 或 BMP 格式。
• 文件大小小于 4 MB。
• 尺寸介于 50 x 50 与 4200 x 4200 像素之间。
• 大小不超过 1000 万像素。
完成以下步骤,可在工作流中使用“计算机视觉”操作:
1. 将 Azure 连接器下的“计算机视觉”操作拖动至工作区,并将指针置于该操作上,然后单击  或双击该操作。
或双击该操作。
或双击该操作。“计算机视觉”窗口随即打开。
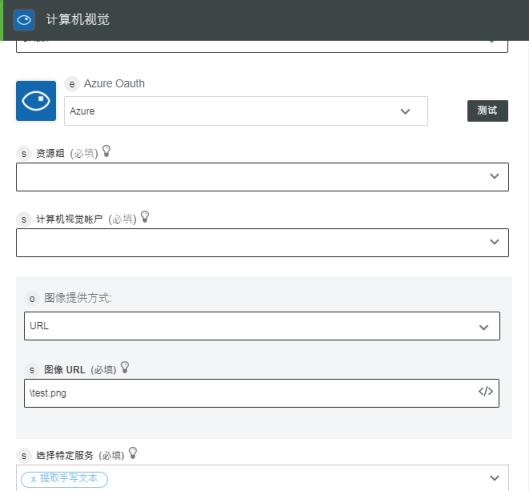
2. 根据需要编辑“标签”。默认情况下,标签名称与操作名称相同。
如果之前已为 Azure 添加了身份验证模式,请从列表中进行选择。
4. 在“资源组”列表中,选择在 Azure 订阅下定义的相应资源组。
5. 在“计算机视觉帐户”字段中,选择相应的计算机视觉帐户。
6. 在“图像提供方式”列表中,选择下列选项之一,然后执行以下操作:
◦ 选择 URL,然后在“图像 URL”字段中,指定一个可公开访问的图像 URL。
◦ 选择“上载文件”,并在“图像文件路径”字段中,映射上一操作的输出以提供图像路径。
7. 在“选择特定服务”列表中,根据要执行的图像分析类型,选择下列计算机视觉服务之一,并执行其相应的任务:
服务 | 任务 |
|---|---|
“分析图像”- 从图像中提取一组丰富的视觉特征。 | a. 在“视觉特征”列表中,选择要用于图像分析的特征: ◦ “类别”- 根据类别分类法对图像内容进行分类。 ◦ “说明”- 通过完整的英语句子来描述图像内容。 ◦ “颜色”- 确定图像是黑白图像还是彩色图像,如果是彩色图像,则检测主导色和主题色。 ◦ “标记”- 通过含有描述图像内容字词的详细列表来标记图像。 ◦ “人脸”- 检测图像中是否存在人脸。 ◦ “图像类型”- 检测图像是剪贴画还是线条画。 ◦ “成人”- 检测图像是否为赤裸裸的色情图像,或包含性暗示内容。 ◦ “对象”- 检测图像中的各种对象。 单击“添加”可添加多个视觉特征。或者,单击  可删除已添加的任何视觉特征。 可删除已添加的任何视觉特征。b. 在“详细信息”下,单击“添加”,然后在下列域特定详细信息中选择一个要包含的详细信息: ◦ “名人”- 标识在图像中检测到的名人。 ◦ “地标”- 标识图像中的重要地标。 单击“添加”可添加多个详细信息。或者,单击 可删除已添加的详细信息。 |
“按领域分析图像” 通过应用域特定模型来识别图像中的内容。 | a. 在“模型”字段中,指定在分析图像时必须使用到的域特定模型。 b. 在“语言”字段中,选择要用于生成输出的语言。默认情况下,系统会选择“英语”。 |
“描述图像”- 用人类可读的完整句子来描述图像内容。 | a. 在“最大候选者数目”字段中,输入服务必须返回的最大候选描述数量。 b. 在“语言”列表中,选择要用于生成输出的语言。默认情况下,系统会选择“英语”。 |
“检测对象”- 对图像执行对象检测。 | – |
“生成缩略图”- 生成指定图像的缩略图。 | a. 在“宽度”字段中,指定介于 1 到 1024 像素之间的缩略图宽度。建议指定的值不低于 50。 b. 在“高度”字段中,指定介于 1 到 1024 像素之间的缩略图高度。建议指定的值不低于 50。 c. 在“智能裁剪”列表中,选择 true 可启用智能裁剪。 如果不想启用智能裁剪,请选择 false。 |
“提取打印文本 (OCR)”- 检测图像中的文本,并将识别出的字符提取到计算机可读的字符流中。 | a. 在“语言”列表中,选择图像中文本的语言。默认情况下,系统会选择“未知”。 b. 在“检测方向”列表中,选择 true 以检测图像中的文本方向,并在进行进一步处理之前对其进行更正。 如果不希望服务检测图像中的文本方向,请选择 false。 |
“提取手写文本”- 从图像中提取手写文本。 | – |
“标记图像”- 生成与图像内容相关的标记列表。 | a. 在“语言”列表中,选择要用于生成输出的语言。默认情况下,系统会选择“英语”。 |
“获取关注领域”- 返回图像中最重要区域周围的边界框。 | – |
8. 单击“完成”。
输出架构
每个“计算机视觉”服务都有自己的输出架构。
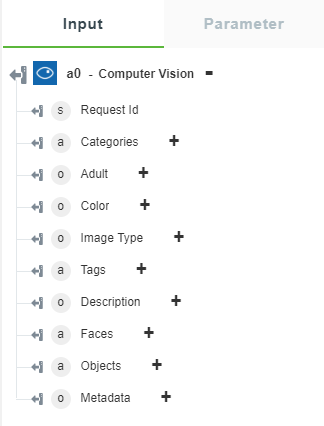
• “分析图像”- 返回所选的视觉特征。
下图显示了示例输出架构:
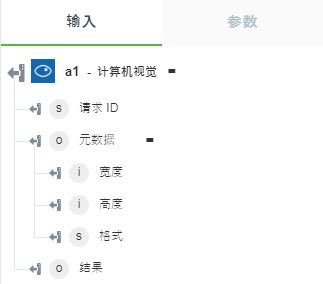
• “按领域分析图像”- 返回图像中识别出的内容。
下图显示了示例输出架构:
• “描述图像”- 返回图像的描述。
下图显示了示例输出架构:
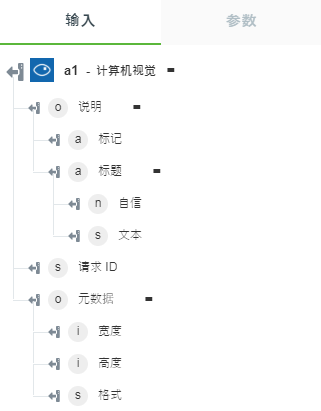
• “检测对象”- 返回对象及其坐标。
下图显示了示例输出架构:

• “生成缩略图”- 返回缩略图。
下图显示了示例输出架构:

• “提取打印文本 (OCR)”- 返回从图像中提取的文本。
下图显示了示例输出架构:
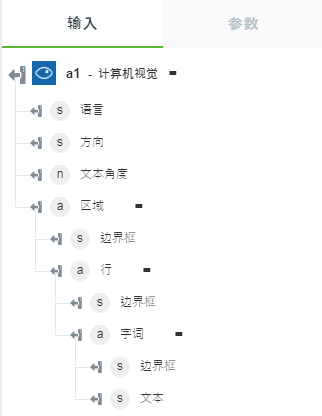
• “提取手写文本”- 返回图像中的手写文本。
下图显示了示例输出架构:
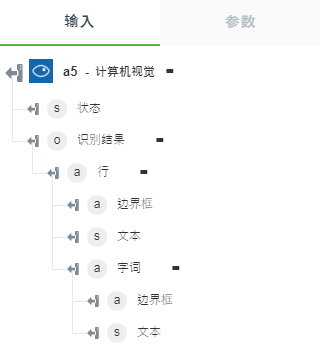
• “标记图像”- 返回图像中检测到的标记。
下图显示了示例输出架构:
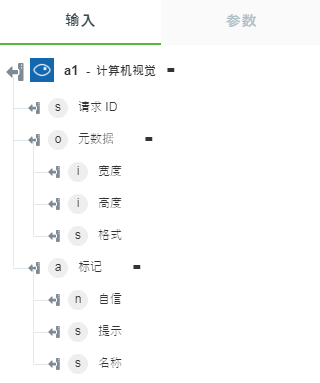
• “获取关注领域”- 返回图像中最重要区域周围的坐标。
下图显示了示例输出架构: