使用 DataStax Enterprise 作为持久化方案提供工具
概述
如果您的模型需要大数据可扩展性,可通过 ThingWorx 中的扩展导入将 DataStax Enterprise (DSE) 用作
持久化方案提供工具。扩展 DsePersistenceProviderPackage.zip 构建为使用 Cassandra (非开源代码/社区版本) 的 DataStax Enterprise 版本,该版本将 Solr 搜索引擎作为集成产品。DSE 是基于 Apache Cassandra 构建的大数据平台,可管理实时数据、分析数据和企业搜索数据。
Cassandra 是一个可扩展的开源 NoSQL 数据库,可以管理多个数据中心和云中的大量数据。Cassandra 运行简单,具有连续可用性和线性可扩展性,可以跨多台商用服务器而不会出现故障点,同时提供强大的数据模型以实现最大的灵活性和快速的响应时间。
|
|
DSE 入门需要您注册、安装和配置 DSE。此进程的大部分操作将独立于 ThingWorx 执行,且会在此进行记录。
|
规划 DataStax Enterprise 部署需要首先了解其体系结构,并且明确与常规关系数据库相比所存在的差异。如果您是初次接触 Cassandra,则 DataStax 学院提供的免费在线课程不失为良好的开端。具体而言,
以下部分将指导您完成一些细节:
•
http://datastax.com/documentation/cassandra/2.0/cassandra/architecture/architecturePlanningAbout_c.html
DSE 和 ThingWorx 入门概览
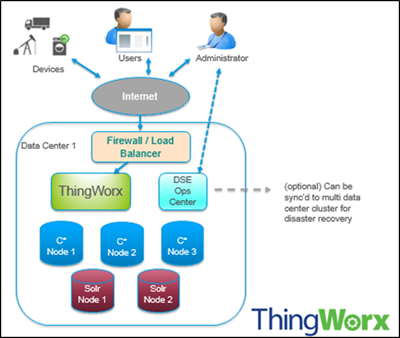
涉及 DSE 的配置时,将在本文档中使用以下术语:
• 节点 - 存储数据的位置。它是 Cassandra 的基本基础架构组件。
• 数据中心 - 相关节点的集合。数据中心可以是物理数据中心,也可以是虚拟数据中心。不同的工作负载应该使用单独的数据中心,即物理数据中心或虚拟数据中心。复制将通过数据中心进行设置。使用单独的数据中心可防止 Cassandra 事务受其他工作负载的影响,并使得各个请求保持紧密联系,以降低延迟。数据可以写入到多个数据中心,具体取决于复制因子。但是,数据中心永远不应跨越物理位置。
• 群集 - 一个群集包含一个或多个数据中心。它可以跨越多个物理位置。
ThingWorx 中 DSE 实现的高级进程
1. 确定 DSE 是否为适用于您的数据的解决方案。有关其他信息,请参阅大小设定和计划部分。
2. 注册并安装 DSE。
此进程独立于 ThingWorx 执行。此处提供了一个部署示例。
3. 将 DSE 持久化方案提供工具扩展导入到 ThingWorx。
4. 在 ThingWorx 中创建连接 DSE 数据存储的持久化方案提供工具实例。
5. 在 ThingWorx 中配置持久化方案提供工具的设置。下表中提供了有关设置的详细信息。
您可以为流、值流和数据表配置存储段设置。这些设置会覆盖 DSE 持久化方案提供工具实例配置。 |
名称 | 默认值 | 说明 | ||
|---|---|---|---|---|
连接信息 | ||||
Cassandra 群集主机 | 192.168.234.136,192.168.234.136 | Cassandra 群集的 IP 地址。这些是 DSE 设置期间配置的 IP 地址或主机名称,用于安装 Cassandra 群集。 | ||
Cassandra 群集端口 | 9042 | 在 DSE 设置期间配置的 Cassandra 群集的端口,用于安装 Cassandra 群集。 | ||
Cassandra 用户名 | 不适用 | 此为可选项,除非您要在群集上启用身份验证。在这种情况下,该字段为必填字段。
| ||
Cassandra 密码 | 不适用 | 此为可选项,除非您要在群集上启用身份验证。在这种情况下,该字段为必填字段。(请参阅上述内容。) | ||
Cassandra 密钥空间名称 | thingworxnd | ThingWorx 数据指向的位置。类似于关系数据库中的架构。
| ||
Solr 群集 URL | http://localhost | 如果正在使用数据表,请提供 IP 或完全限定的主机名称,包括 DSE 设置期间配置的用于安装 Cassandra 群集的域或 IP。 | ||
Solr 群集端口 | 8983 | 如果正在使用数据表,请提供 DSE 设置期间配置的用于安装 Cassandra 群集的端口。 | ||
Cassandra 密钥空间设置 | 同步复制 = {'class':'NetworkTopologyStrategy', 'Cassandra':1, 'Solr':1} | |||
Cassandra 一致性级别 | {'Cluster' : { 'read' : 'ONE', 'write' : 'ONE' }} | 节点数的读取和写入一致性级别。
| ||
CQL 查询结果限制 | 5000 | Cassandra 查询语言查询结果限制指定了查询数据时可返回的行数。这样可以增强 ThingWorx 的稳定性,因为不允许返回可能导致平台性能问题的大型结果集。 | ||
保持连接 | true | 有助于保持与 Cassandra 群集连接的正常运行,特别是跨越防火墙的非活动连接可能会断开。
| ||
连接超时 (毫秒) | 30000 | 初始连接超时 (以毫秒为单位)。取决于 ThingWorx 和 Cassandra 群集之间的网络延迟。 | ||
压缩算法 | 无 | 当 ThingWorx 将数据发送到群集中时,有三个选项: • Lz4 压缩 • 快速压缩 • 不压缩 如果 ThingWorx 和 Cassandra 群集之间的网络带宽较低,则使用压缩可提高吞吐量。
| ||
查询重试最大次数 | 3 | 为查询启用的最大重试次数。默认值为 3。 | ||
本地核心连接数 | 4 | 能够读取/写入数据的最小连接数。 | ||
本地最大连接数 | 16 | 能够读取/写入数据的最大连接数 | ||
远程核心连接数 | 2 | 能够读取/写入数据的最小远程连接数。 | ||
远程最大连接数 | 16 | 能够读取/写入数据的最大远程连接数。 | ||
启用追踪 | false | 日志记录。可用于调试。 | ||
异步请求最大次数 | 1000 | |||
典型流设置 | ||||
缓存初始大小 | 10000 | 初始缓存大小。这取决于源的数量。
| ||
缓存最大大小 | 100000 | 最大缓存大小。控制内存使用情况。 | ||
缓存并发性 | 24 | 单次可以访问的线程数。最小值应反映为最大远程连接数设置的值。 | ||
典型流默认值 | ||||
源存储段计数 | 1000 | 可以投入到存储段的源。源的数量等于需要执行的查询次数。例如,如果您有 100,000 个源,此字段将确定所使用存储段的数量。
| ||
存储段间隔时间 (小时) | 24 | 创建存储段的时间 (以小时为单位)。取决于源存储段间隔的设置方式。例如,如果将存储段间隔时间设置为 24,则每 24 小时创建一个存储段。目标是尝试不超过 200 万个数据点。因此,取决于每个值流或典型流的数据采集速率 (R/秒):存储段间隔时间 = 2 mil/(R * 60 * 60)
| ||
数据表默认值 | ||||
数据表存储段计数 | 3 | 数据表可以拆分为存储段。这允许在 DSE 节点内传播数据表。建议使用的值高于群集中节点数,以便在节点数随载荷增加而增加时能够传播数据。另一个要考虑的因素是数据表中预期的行数。考虑限制为每个存储段 200,000 行。此处为默认设置。可以为每个数据表指定存储段计数。
| ||
值流设置 | ||||
缓存初始大小 | 10000 | 初始缓存大小。这取决于每个源的属性数与源的数量的乘积。 | ||
缓存最大大小 | 100000 | 最大缓存大小。控制内存使用情况。 | ||
缓存并发性 | 24 | 单次可以访问的线程数。 | ||
值流默认值 | ||||
源存储段计数 | 1000 | 可以投入到存储段的源。源的数量等于需要执行的查询次数。例如,如果您有 100,000 个源,此字段将确定所使用存储段的数量。
| ||
属性存储段计数 | 1000 | 存储段的数量取决于每个值流的属性数量和查询模式。如果存在跨属性查询,则较小的存储段大小即可使性能达到最佳。 | ||
存储段间隔时间 (小时) | 24 | 存储段的大小。取决于源存储段间隔的设置方式。例如,如果将存储段间隔时间设置为 24,则每 24 小时创建一个存储段。
| ||
6. 如有必要,请迁移实体和数据。
7. 监控和维护 DSE 实现。此处将介绍创建成功维护计划的最佳做法。