SQL 커넥터
SQL 커넥터를 사용하면 다음 데이터베이스에 연결하여 다양한 데이터베이스 작업을 수행할 수 있습니다.
• PostgreSQL
• SQL Server
• MySQL
• Oracle
Oracle 데이터베이스 사용을 위한 필수조건
Windows
2. 시스템 경로에 이러한 라이브러리를 추가합니다.
3. 새 명령 프롬프트 창에서 echo %PATH% 명령을 사용하여 경로가 업데이트되는지 확인합니다.
4. pm2 restart all --update-env 명령을 실행합니다.
5. ThingWorx Flow 브라우저 페이지를 새로 고칩니다.
|
|
컴퓨터가 재시작될 때마다 pm2 restart all --update-env 명령을 실행합니다.
|
Linux
2. /etc/profile.d 디렉터리 아래에 flow.sh 파일을 만듭니다.
3. flow.sh 파일에서 Oracle 라이브러리에 대한 경로를 추가합니다.
export LD_LIBRARY_PATH=/opt/oracle
4. 새 명령 프롬프트 창에서 echo $LD_LIBRARY_PATH 명령을 사용하여 경로가 업데이트되는지 확인합니다.
5. pm2 restart all --update-env 명령을 실행합니다.
6. ThingWorx Flow 브라우저 페이지를 새로 고칩니다.
커넥터 릴리즈 버전
SQL 커넥터는 8.5 릴리즈에서 제공됩니다.
지원되는 작업
지원되는 트리거
없음
지원되는 승인
기본
SQL 커넥터 연결 추가
각 SQL 커넥터 작업에 대해 SQL 커넥터를 승인해야 합니다. SQL 커넥터를 승인하려면 다음을 수행하십시오.
1. SQL 커넥터에 있는 작업을 캔버스에 끌어 놓고 마우스 포인터로 작업을 가리킨 다음  을 클릭하거나 작업을 두 번 클릭합니다.
을 클릭하거나 작업을 두 번 클릭합니다.
을 클릭하거나 작업을 두 번 클릭합니다.2. 데이터베이스 목록에서 적합한 데이터베이스를 선택합니다.
3. 선택한 데이터베이스 목록에서 새로 추가를 선택합니다.
연결 추가 창이 열립니다.
예를 들어, PostgreSQL을 데이터베이스로 선택한 경우 PostgreSQL 목록에서 새로 추가를 선택합니다.
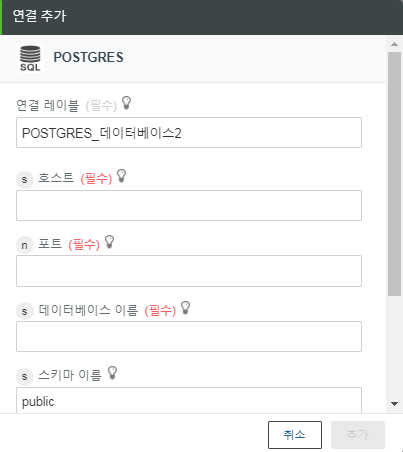
4. 원하는 경우 연결 레이블 필드를 편집합니다.
공백, 특수 문자 및 앞에 오는 숫자는 사용할 수 없습니다.
5. 호스트 필드에 데이터베이스 호스트를 입력합니다.
6. 포트 필드에 데이터베이스 포트를 입력합니다.
7. 데이터베이스 이름 필드에 데이터베이스의 이름을 입력합니다.
Oracle의 경우 데이터베이스 이름 필드의 값은 데이터베이스의 서비스 이름입니다. |
8. 스키마 이름 필드에 스키마 이름을 입력합니다. 기본적으로 이 이름은 다음과 같이 설정됩니다.
◦ PostgreSQL - public
◦ SQL Server - dbo
◦ Oracle - 사용자 이름
다른 사용자의 데이터베이스에 연결하려는 경우 해당 사용자의 사용자 이름을 입력합니다.
MySQL 데이터베이스에는 스키마 이름이 없습니다. |
9. 사용자 이름 및 암호 필드에 데이터베이스 연결을 승인하는 데 사용할 올바른 사용자 이름 및 암호를 입력합니다.
10. 추가를 클릭하여 데이터베이스 연결을 추가합니다.
새 연결이 목록에 추가됩니다.
11. 테스트를 클릭하여 데이터베이스 연결의 유효성을 검사합니다.
SQL 커넥터 사용자 정의
다음 표에는 데이터 유형 및 지원되는 연산자의 목록이 나와 있습니다.
데이터 유형 | 지원되는 연산자 |
|---|---|
• INT • BIGINT • MEDIUMINT • SMALLINT • TINYINT • NUMBER • FLOAT • REAL • DECIMAL • NUMERIC • DOUBLE • DOUBLE PRECISION • SMALLSERIAL • SERIAL • BIGSERIAL • INTEGER • PRECISION • DEC • MONEY • SMALLMONEY | • GREATER THAN • GREATER THAN OR EQUAL TO • LESS THAN • LESS THAN OR EQUAL TO • EQUAL TO • NOT EQUAL TO • BETWEEN • NOT BETWEEN • IN • NOT IN • IS NULL • IS NOT NULL |
• TEXT • TINYTEXT • MEDIUMTEXT • LONGTEXT • NTEXT • CHAR • VARCHAR • VARCHAR2 • NCHAR • NVARCHAR • VARYING • CHARACTER • CHARACTER VARYING | • EQUAL TO • NOT EQUAL TO • LIKE • NOT LIKE • STARTS WITH • ENDS WITH • SUBSTRING • IS NULL • IS NOT NULL |
• DATE • DATETIME • DATETIME2 • TIME • TIMESTAMP WITH TIME ZONE • TIMESTAMP • DATETIMEOFFSET • SMALLDATETIME • YEAR • INTERVAL | • BEFORE • AFTER • BETWEEN • NOT BETWEEN • IN • NOT IN • IS NULL • IS NOT NULL |
다른 모든 데이터 유형 | • EQUAL TO • NOT EQUAL TO • IS NULL • IS NOT NULL |
다음 작업에 대해 모든 데이터 유형에 대한 연산자를 추가할 수 있습니다.
• 행 삭제
• 행 가져오기
• 조인이 포함된 행 가져오기
• 행 업데이트
연산자를 사용자 정의하려면 다음 단계를 수행하십시오.
1. 아래에 나온 대로 data.json 파일을 만듭니다.
{
"DatatypeOperatorConfig": [{
"dataTypeName":"Any_Data_Type",
"supportedDBs":["Database1","Database2"],
"Operators":[{
"id":"OPERATOR_ID",
"value":"OPERATOR"
}]
}]
}
"DatatypeOperatorConfig": [{
"dataTypeName":"Any_Data_Type",
"supportedDBs":["Database1","Database2"],
"Operators":[{
"id":"OPERATOR_ID",
"value":"OPERATOR"
}]
}]
}
예를 들어, 지원되지 않는 데이터 유형인 ROW에 대해 Oracle 데이터베이스에 대한 LIKE 연산자를 추가하려면 data.json 파일이 다음과 같아야 합니다.
{
"DatatypeOperatorConfig": [{
"dataTypeName":"RAW",
"supportedDBs":["oracle"],
"Operators":[{
"id":"LIKE",
"value":"LIKE"
}]
}]
}
"DatatypeOperatorConfig": [{
"dataTypeName":"RAW",
"supportedDBs":["oracle"],
"Operators":[{
"id":"LIKE",
"value":"LIKE"
}]
}]
}
2. data.json 파일을 저장한 경로를 찾아서 명령 프롬프트를 시작합니다.
3. 사용 사례에 따라 다음 명령 중 하나를 실행합니다.
시나리오 | 명령 |
|---|---|
특정 데이터베이스 호스트 이름 및 포트 사용자 정의 | flow-deploy settings file upload -f <data.json 파일의 경로> -t <ThingWorx Flow URL> -u <ThingWorx 관리자 사용자> -p <ThingWorx 관리자 사용자 암호> -c database - s <데이터베이스 호스트><데이터베이스 포트> 예: flow-deploy settings file upload -f data.json -t <ThingWorx Flow URL> -u <ThingWorx 관리자 사용자> -p <ThingWorx 관리자 사용자 암호> -c database -s localhost32776 |
데이터베이스의 모든 연결된 인스턴스 사용자 정의 | flow-deploy settings file upload -f <data.json 파일의 경로> -t <ThingWorx Flow URL> -u <ThingWorx 관리자 사용자> -p <ThingWorx 관리자 사용자 암호> -c database -d |
4. 브라우저를 새로 고칩니다.
이제 지원되는 작업 중 하나를 워크플로 편집기로 끌면 연산자 목록에 연산자가 보여야 합니다.