ThingWorx 高可用性
ThingWorx 高可用性の概要
重要なモノのインターネット (IoT) システムの停止時間を削減するため、ThingWorx が高可用性 (HA) 環境で動作するように設定できます。このガイドでは、ThingWorx HA 展開を構成する ThingWorx システムとコンポーネントに必要とされる HA の考慮事項について説明します。
すべての HA 展開では、機能とスケールの要件を満たすためだけに設計された展開と比べて追加リソースが必要です。これらの追加リソースには、ハードウェアベースのもの (サーバー、ディスク、ロードバランサーなど) とソフトウェアベースのもの (同期化サービスやロードバランサーなど) があります。HA 展開内で単一障害点が存在することがないように追加リソースが構成されます。
すべての HA 展開は、各自の展開におけるアプリケーションのアップタイム要件の分析結果である SLA (サービス品質保証契約) に基づいていなければなりません (たとえば、毎月何時間システムをオフラインにできるか? これはシステムの失敗、アプリケーションのアップグレード、またはその両方で許容される非稼動時間か?)。HA システムに必要な追加リソースの数は、HA システムが達成する必要がある SLA によって異なります。一般に、SLA が高度化するにしたがい、それを実現するためのリソースへのニーズも大きくなります。
定義
• 高可用性
希望どおり長時間稼動し続けるシステムまたはコンポーネント。
• アクティブ/アクティブ
同時に機能可能な同じアプリケーションの複数のインスタンス。
• アクティブ/パッシブ
一度に機能可能なアプリケーションの 1 つのインスタンス。追加のインスタンスを使用可能であり、必要に応じてサービスを継承できます。
• リーダーまたはマスター
アクティブ/パッシブ HA 構成内の、すべてのトラフィックがルーティングされるアクティブサーバー。
• スタンバイ
アクティブ/パッシブ HA 構成内の、待機中で現在のリーダーが失敗した場合にサービスを継承するサーバー。
• 仮想 IP アドレス
アプリケーションを表す IP アドレス。仮想 IP アドレスを使用するクライアントは、通常はロードバランサーにルーティングされ、ロードバランサーはアプリケーションを実行しているサーバーにリクエストを転送します。
• ロードバランサー
ネットワークトラフィックを受信して、これを受け付ける準備が整っているアプリケーションに分散するデバイス。アクティブ/パッシブ HA 構成では、ロードバランサーはトラフィックを現在のリーダーに転送します。アクティブ/アクティブ HA 構成では、ロードバランサーはトラフィックを多数のアプリケーションのいずれかに転送します。
• フェールオーバー
バックアップ動作モード。プライマリコンポーネントが失敗またはスケジュールされたダウンタイムによって使用できなくなった場合、システムコンポーネント (プロセッサ、サーバー、ネットワーク、またはデータベース) の機能はセカンダリシステムコンポーネントによって実行されます。
高可用性での ThingWorx 参照アーキテクチャ
以下の図に、高可用性構成の ThingWorx を示します。
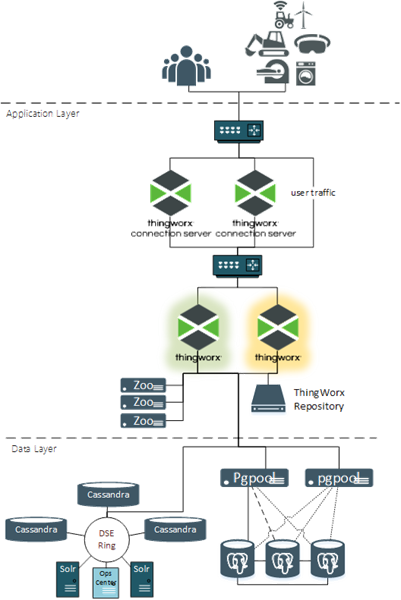
この構成におけるコンポーネントおよび HA 展開でのそのロールを以下に示します。
• ユーザーおよびデバイス - HA 機能におけるロールはありません。これらの観点からは何の変化もありません。プライマリ ThingWorx サーバーに変更があった場合でも、これらは必ず同じ URL と IP アドレスを使用します。
• ファイアウォール - HA 機能はなく、オプションと見なすことができます。ファイアウォールは通常はセキュリティの要件を実装するために配置されます。
• ロードバランサー - ロードバランサーはサポートしているアプリケーションの仮想 IP アドレスを管理します。その仮想 IP アドレスにルーティングされるすべてのトラフィックが、それを受信可能なアクティブなアプリケーションに転送されます。
• ThingWorx Connection Servers - アセットから Web ソケットトラフィックを受信し、ThingWorx Platform にルーティングします。Connection Server はアクティブ/アクティブ構成で稼動できます。アセットが特定の Connection Server に転送された後は、そのアセットは必ず同じ Connection Server を使用します。そのサーバーがオフラインになった場合、使用可能な別の Connection Server にアセットがリダイレクトされなければなりません。
• ThingWorx Foundation - すべてのユーザートラフィックとアセットトラフィックを受信します。ThingWorx Foundation は、1 台のリーダーサーバーと 1 台以上のスタンバイサーバーから成るアクティブ/パッシブ構成で動作します。リーダーサーバーはオンラインでトラフィックを受信します。スタンバイサーバーはアプリケーション実行中はウォームアップ状態で動作していますが、データベースへのアクティブな接続はなく、トラフィックは受信しません。ロードバランサーはすべてのトラフィックをリーダーにルーティングします。リーダーがオフラインになった場合、スタンバイがリーダーにプロモートされてトラフィックがルーティングされるようになります。
• ThingWorx リポジトリ - ThingworxPlatform、ThingworxStorage、ThingworxBackupStorage などの必須の保存場所や、実装をサポートするために追加された保存場所。HA 環境では、ThingWorx リポジトリはすべての ThingWorx サーバー (リーダーおよびスタンバイ) が等しくアクセス可能な共通の保存場所に存在していなければなりません。
• Apache ZooKeeper - ZooKeeper は、ThingWorx が任意のタイミングで ThingWorx サーバーのいずれかをリーダーとして選出するときに使用される一元的調整サービスです。ZooKeeper クライアントは、各 ThingWorx サーバーに組み込まれており、ハートビートを維持し、現在の ThingWorx リーダーの失敗など、構成内での変更に対応します。
• PostgreSQL - HA 構成では、PostgreSQL はホットスタンバイ構成の 2 つ以上のサーバーノード上で動作します。1 つのノードがすべての書き込みトラフィックを受信し、その他のノードのいずれかがすべての読み取りトラフィックを受信できます。各ノードが最新の状態を維持するため、すべてのノード間でストリーミングレプリケーションがアクティブ化されます。
• Pgpool-II - これは PostgreSQL HA 構成でのみ使用されます。Pgpool-II ノードは ThingWorx リクエスト (読み取りおよび書き込み) を受信して適切な PostgreSQL ノードに転送します。各 PostgreSQL ノードの正常性も監視し、いずれかのノードがオフラインになった場合、フェールオーバータスクとターゲット変更タスクを開始できます。
• Microsoft SQL Server (図には示されていません) - Microsoft フェールオーバーを使用して、少なくとも 1 台の MS SQL サーバーがオンラインで稼動しているようにします。
• DataStax Enterprise (DSE) - ThingWorx HA 構成では DSE の実装は必要ありません。実装の取得要件を満たす必要がある場合、これを HA 構成にします。一般的な DSE 実装は HA のほとんどの要件を満たしています。コンテンツを収集する複数の Cassandra ノードと 2 つ以上の Solr ノードがあります。DSE 設計ではすべてのコンテンツが 1 つ以上のその他のノードにレプリケーションされます。
ThingWorx Platform バージョン 8.5.0 の時点で、DataStax Enterprise は販売対象でなくなっており、今後のリリースではサポートされません。詳細については、
販売終了に関するアーティクルを参照してください。 |
インストール前の要件
注記および警告:
• HA プロセスの手順は、HA 構成のリレーショナルデータベース (PostgreSQL、Microsoft SQL Server、および DataStax Enterprise) の使用経験があるデータベース管理者 (DBA) を対象としています。インストール、最適化、高可用性クラスタなどについての知識が必要です。
• ここでは、HA 環境の展開に関するガイダンスを提供します。運用環境でさらなるパフォーマンスチューニングが必要な場合がありますが、これについては説明していません。
• 詳細なステップは、参照用の例であり、QA/サンドボックス環境で使用することを目的としています。インストール担当者は、運用環境で最適なパフォーマンスを得るために、必要に応じてコマンドおよび設定を編集できます。
• 本番環境で使用する前に、すべてのフェールオーバー設定を完全にテストして検証しなければなりません。
• このプロセスの手順では、失敗したリーダーが修正されてリーダーの位置に戻されるまでのフェイルバックのシナリオについては説明していません。ここでは失敗したコンポーネントが修正されて非リーダーコンポーネントとしてサービスに戻ることを前提としています。
サポートされるオペレーティングシステム
一般的な HA の要件
仮想 IP アドレス
• ユーザーおよびアセットから Connection Server (Connection Server が使用されている場合)
• Connection Server から ThingWorx Foundation
• ThingWorx Foundation から PostgreSQL HA (PostgreSQL が使用されている場合)
• ThingWorx Foundation から Microsoft SQL Server HA (Microsoft SQL Server が使用されている場合)
ハードウェアの要件
ここで示す手順では、ThingWorx HA 構成で完全なハードウェア冗長化が実現していることを前提としています。
• ハードウェアレベルでの単一障害点を回避するため、アプリケーションの各インスタンスが別個のハードウェアで動作していなければなりません。たとえば、ThingWorx サーバーは、物理、仮想、クラウドベースのいずれにかかわらず、同じ物理ハードウェア上で動作してはなりません。
• ハードウェア失敗のリスクを緩和するため、この要件は ThingWorx HA 構成のすべてのアプリケーション (ThingWorx、PostgreSQL、DataStax Enterprise、ZooKeeper など) で必要とされます。
• ここで示す手順では、冗長ルータ、スイッチ、電源などが使用されていることを前提としています。
HA 構成での ThingWorx プロパティ
フェールオーバー時にデータが失われないようにするには、ThingWorx プロパティを永続に設定する必要があります。永続でない場合、プライマリサーバーからセカンダリサーバーへのフェールオーバーによってメモリ内の値がクリアされます。
PostgreSQL の要件
• RHEL または Ubuntu 環境でインストールされている Pgpool-II および PostgreSQL DB。
• サポートされているバージョンの PostgreSQL が動作している 2 台以上の DB ホストサーバー。3 台が推奨されます。
• Pgpool-II 3.7. <最新> を実行している、ウォッチドッグが設定された 2 台のサーバーが一般的です。ここでは、これが例として示されていますが、Pgpool-II を使用しないその他の HA 構成もオプションとして選択可能です。
Microsoft SQL Server の要件
• サポートされているバージョンの Microsoft SQL Server が動作している 2 台以上の DB ホストサーバー。
• Microsoft SQL Server は Microsoft の以下のいずれかの HA 手法で動作するように設定されています。
◦ AlwaysOn フェールオーバークラスタインスタンス
◦ AlwaysOn 可用性グループ
DataStax Enterprise の要件
• DataStax Enterprise クラスタ 1 つにつき 5 つ以上のノード:
◦ 3 つの Cassandra ノード
◦ 2 つの Solr ノード
◦ (オプション) 管理作業のための 1 つの DSE OpsCenter ノード (OpsCenter は動作に不可欠ではなく、高可用性構成を必要としないので)。
InfluxDB の要件
• 2 つ以上のメタノード (ほとんどの用途では 3 つが推奨されます)
• 2 つ以上のデータノード (偶数のデータノードが推奨されます)
• 一般的な展開では 3 つのメタノードおよび偶数のデータノードが必要です