Using InfluxDB as the Persistence Provider
Overview
If your system intensively deals with time series data and your implementation heavily depends on value streams or streams for persistence/retrieval of data, we recommend using InfluxDB as the persistence provider in ThingWorx. InfluxDB is a high-performance data store written specifically for time series data. It allows for high throughput ingest, compression, and real-time querying of that same data. InfluxDB is used as a data store for any use case involving large amounts of time-stamped data, including DevOps monitoring, log data, application metrics, IoT sensor data, and real-time analytics. It also provides other capabilities, including Data Retention Policies (RP) an so on. The InfluxDB enterprise offers high availability and highly scalable clustering solution for time series data needs.
|
|
ThingWorx 8.4.0 and later is required to use InfluxDB.
|
The InfluxPersistenceProviderPackage is available as part of default installation for PostgreSQL or MSSQL.
|
|
The InfluxDB data provider currently supports value streams and streams only. The support for data tables, wikis, and blogs is not available.
|
|
|
The InfluxDB data provider does not currently support export functionality.
|
|
|
InfluxDB is not supported as a property provider.
|
|
|
InfluxDB data provider currently supports a retention policy with name "autogen" only. While creating the database to use with data provider, you can specify the policy name and other policies such as replication factor and so on .
|
InfluxDB Enterprise and ThingWorx Starting Landscape
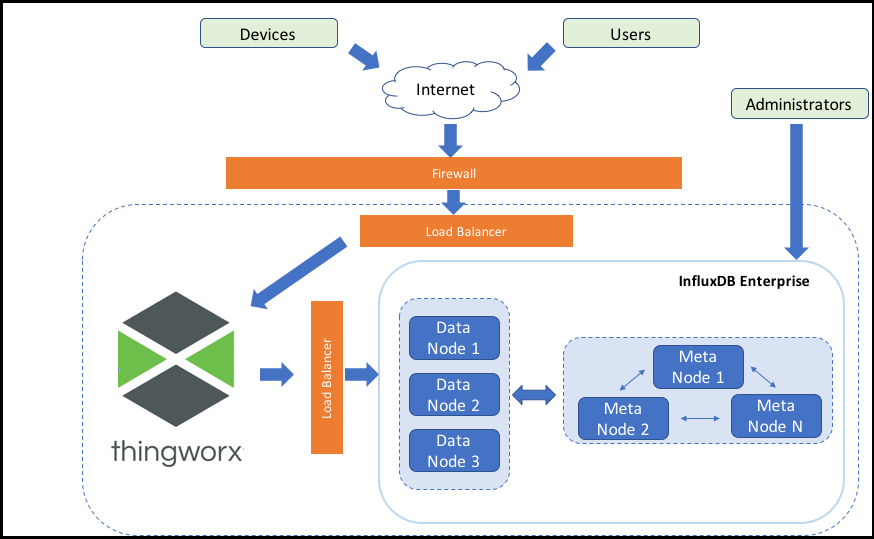
The diagram above includes InfluxDB Enterprise. For InfluxDB open source, the architecture diagram would be the same, except that it only works with one node. |
The following terms are used in this documentation when referring to the configuration for InfluxDB Enterprise:
• Load Balancer— InfluxDB Enterprise does not function as a load balancer. An administrator needs to configure it.
• Cluster— An InfluxDB Enterprise cluster is comprised of two types of nodes: meta nodes and data nodes.
• Data Nodes— All the raw time series data lives there. For high availability, you need a replication factor of at least two.
• Meta nodes— These nodes have a simple job, to keep state consistent. They contain only basic information about state, such as retention policies, users, and databases. In a high availability environment, at least three meta nodes are needed.
Find more information about HA at https://www.influxdata.com/blog/understanding-influxenterprise-what-is-a-cluster/.
Benefits of Using InfluxDB Enterprise
If you are looking for a data store for higher volumes and velocity data than what is currently available with other databases, then the following benefits are possible with InfluxDB Enterprise:
• Higher rate of ingestion of data
• You can have more than one data repository for run time data. For example, you can keep relational data in PostgreSQL, while using InfluxDB for high volume stream and value stream data. When you define a stream or value stream, ThingWorx uses the default run time data store provider, but you can configure it to use any defined persistence provider.
You can still export data from other data providers and import to InfluxDB. ThingWorx handles the data abstraction. |
• Cloud-friendly architecture (horizontal scale, only with InfluxDB Enterprise)
Installing and Configuring InfluxDB
It is responsibility of whomever installs Influx database to read and understand all security related documentation provided for InfluxDB. PTC strongly recommends installing and configuring InfluxDB using secure configurations including use of username and strong password. |
This process assumes ThingWorx is installed. See Installing ThingWorx. |
1. Download and install InfluxDB.
InfluxDB is not supported in Windows. The steps below use UNIX OS. |
◦ InfluxDB Open Source (single node): Reference https://docs.influxdata.com/influxdb/v1.7/introduction/installation/
Download links:
◦ InfluxDB Enterprise (high availability): Reference https://docs.influxdata.com/enterprise_influxdb/v1.7/install-and-deploy/production_installation/
Download links-Data node:
Download links-Meta node:
2. Create a database inside InfluxDB. Obtain and run the thingworxInfluxDBSetup.sh script to create the database in InfluxDB.
The thingworxInfluxDBSetup.sh script is available on the PTC Support Portal in the install folder of the software download package. |
The following example command creates a database with the default retention policies:
CREATE DATABASE thingworx with DURATION 365d REPLICATION 1 SHARD DURATION 30d NAME autogen
3. Create a InfluxDB user. The following example command creates a user:
CREATE USER twadmin WITH PASSWORD 'password' WITH ALL PRIVILEGES
4. In ThingWorx Composer, create a new persistence provider.

5. In the Persistence Provider Package field, select InfluxPersistenceProviderPackage.
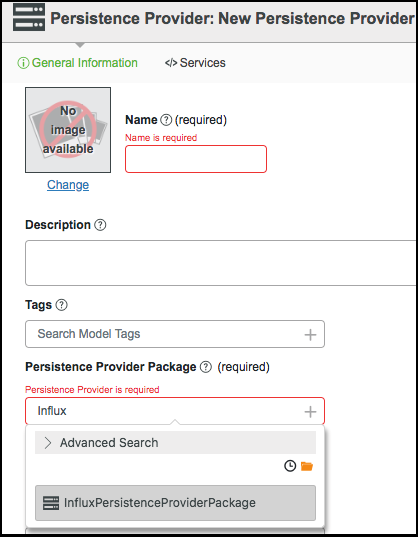
6. Click Save.
7. Click the Configuration tab and configure the connection information as necessary and save. Reference the configuration options in the tables below.
If you are using a persistence provider instance (created using InfluxDB persistence provider package) as the default persistence provider, you can edit the following stream and value stream queue configurations settings. These edits then apply to all streams and value streams. You cannot change these settings for a specific stream or value stream.
When switching the persistence provider of a value stream (for example, from ThingworxPersistenceProvider to InfluxPersistenceProviderPackage), any Thing that implements a value stream must call the RestartThing service to retrieve entries written to the new persistence provider. If the Things are not restarted, entries may be written to the database, but they are not retrieved until the Thing is restarted. |

Name | Description | Default Value |
|---|---|---|
Connection URL | The URL of the database from which you should acquire connections. | http://localhost:8086 |
Database Schema | Schema to connect. | thingworx |
Username | User name for acquiring a database connection. | thingworx |
Password | Password for acquiring a database connection. | n/a |
Fetch Size of Data from the Persistence Provider | Fetch size of data from the persistence provider. | 5000 |
Time for Connection Timeout | Time, in seconds, for a connection timeout. | 10 |
Time for Read Timeout | Time, in seconds, for a read timeout. | 10 |
Time for Write Timeout | Time, in seconds, for a write timeout. | 10 |
Name | Description | Base Type | Default Value | ||
|---|---|---|---|---|---|
Max Queue Size | Maximum number of stream entries to queue. Once the specified value is reached, the subsequent entries are rejected. | Number | 250000 | ||
Max Wait Time Before Flushing Stream Buffer (millisec) | Number of milliseconds the system waits before flushing the stream buffer. | Number | 2000 | ||
Number of Processing Threads | Number of processing threads dedicated to the stream.
| Number | 5 | ||
Max no. of Items Before Flushing Stream Buffer | Maximum number of items to accumulate before flushing the stream buffer. | Number | 1000 | ||
Max no. of Stream Writes in Process Block | Maximum number of stream writes to process in one block. | Number | 2500 | ||
Buffer Status Scan Rate (millisec). | The buffer status is checked at the specified rate value in milliseconds. | Number | 5 |
Name | Description | Base Type | Default Value | ||
|---|---|---|---|---|---|
Max Queue Size | Maximum number of value stream entries to queue. Once the specified value is reached, the following entries are rejected. | Number | 250000 | ||
Max Wait Time Before Flushing Value Stream Buffer (millisec) | Number of milliseconds the system waits before flushing the value stream buffer. | Number | 2000 | ||
Number of Processing Threads | Number of processing threads allocated to the value stream.
| Number | 5 | ||
Max no. of Items Before Flushing Value Buffer | Maximum number of items to accumulate before flushing the value stream buffer. | Number | 500 | ||
Max no. of Value Stream Writes in Process Block | Maximum number of items to process in one block. | Number | 2500 | ||
Buffer Status Scan Rate (millisec) | The buffer status is checked at the specified rate value in milliseconds. | Number | 5 |
8. Click the General Information tab and select the Active check box.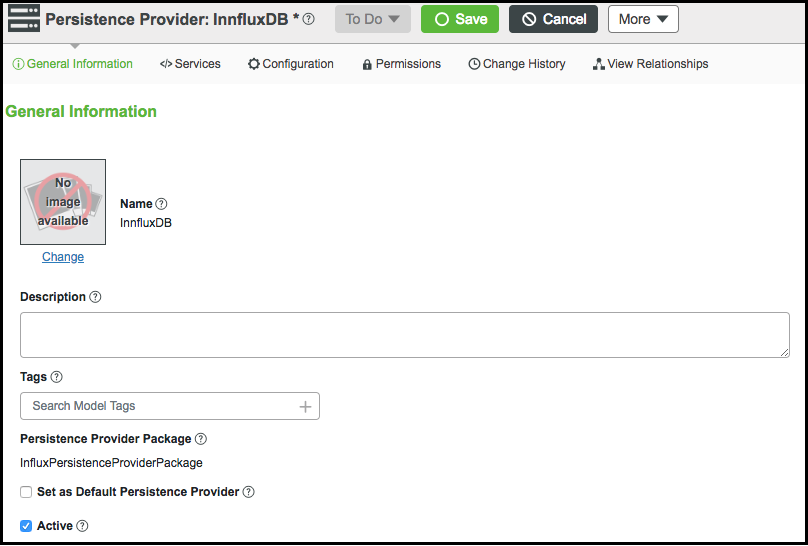
9. Click Save.
Best Practices
Series Limit
Series is the total number of unique combinations of Things and associated value streams logged into InfluxDB. InfluxDB performs well with high data volume directed to a small amount of Things and Thing properties, such as 10Ks or 100Ks. The total number of series is limited to 1 million by default in InfluxDB. You can increase the limit, but the performance of InfluxDB decreases as the number of series goes beyond this limit.
If you have a large number of Things and properties, you can choose the ones with the highest data volume and point only them to InfluxDB to take the pressure off from PostgreSQL or MSSQL.
Alternatively, if you want to divide the series to multiple servers, you can have multiple instances of InfluxDB Data Provider pointing to different InfluxDB server instances.
Write Limit
There are 100K writes per second with a 60gb memory VM with 32 cores. Going beyond this limit can cause problems in ThingWorx and it can run out of resources to handle any request or job, such as writing to the database. At that point, ThingWorx becomes stalled while InfluxDB is still writing to the database. This is not an issue with PostgreSQL because PostgreSQL becomes the bottleneck and ThingWorx is never able to get to the point of being out of resources to handle the tasks inside.
SSL/Secure Connection
InfluxDB supports SSL and HTTPS connections. You can enable SSL and HTTPS connections to increase security if the network between ThingWorx and InfluxDB is not supported. A self-signed certificate is adequate, if the signing private key is kept secure.
Known InfluxDB Limitations on Property Base Types
You can not change the base type of a property after it has been logged to a value stream. See https://github.com/influxdata/influxdb/issues/3460for more information.
Purging Properties
The PurgeAllPropertyHistory, PurgeSelectedPropertyHistory, and PurgePropertyHistory services can be used to purge properties from InfluxDB. Use the startDate and endDate parameters to specify a range.