Using DataStax Enterprise as the Persistence Provider
Overview
|
|
As of version 8.5.0 of ThingWorx platform, DSE is no longer for sale and will not be supported in a future release. Reference the End of Sale article for more information.
|
If your model requires big data scalability, you can use DataStax Enterprise (DSE) as the persistence provider via an extension import in ThingWorx. The extension DsePersistenceProviderPackage.zip is built to use the DataStax Enterprise edition of Cassandra (not the Open Source/Community Edition), which has the Solr search engine as an integrated offering. DSE is a big data platform built on Apache Cassandra that manages real-time, analytics, and enterprise search data.
Cassandra is a scalable open source NoSQL database that can manage large amounts of data across multiple data centers and the cloud. Cassandra delivers continuous availability, linear scalability, and operational simplicity across many commodity servers with no single point of failure, along with a powerful data model designed for maximum flexibility and fast response times.
|
|
Getting started with DSE requires you to register, install, and configure DSE. Most of this process is performed independently of ThingWorx and is documented here.
|
Planning for DataStax Enterprise deployment needs to start with understanding its architecture and specifically, the differences compared to regular Relational Databases. If you are new to Cassandra, a good place to start is the free online courses offered by DataStax Academy. Specifically,
The following section will guide you through some of the specifics:
DSE and ThingWorx Starting Landscape
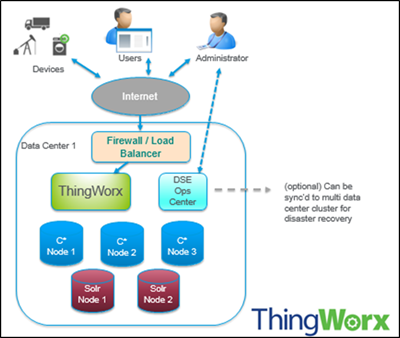
The following terms are used in this documentation when referring to the configuration for DSE
• Node-Where you store your data. It is the basic infrastructure component of Cassandra.
• Data center- A collection of related nodes. A data center can be a physical data center or virtual data center. Different workloads should use separate data centers, either physical or virtual. Replication is set by data center. Using separate data centers prevents Cassandra transactions from being impacted by other workloads and keeps requests close to each other for lower latency. Depending on the replication factor, data can be written to multiple data centers. However, data centers should never span physical locations.
• Cluster- A cluster contains one or more data centers. It can span physical locations.
High Level Process for DSE Implementation in ThingWorx
1. Determine if DSE is the right solution for your data. Refer to the sizing and planning sections for additional information.
2. Register and install DSE.
This process is performed independently of ThingWorx. A deployment example is provided.
3. Import the DSE persistence provider extension into ThingWorx.
4. Create a persistence provider instance in ThingWorx that will connect the DSE data store.
5. Configure the settings for the persistence provider in ThingWorx. Setting details are provided in the table below.
For streams, value streams, and data tables, you can configure bucket settings. These settings override the DSE persistence provider instance configuration. |
Name | Default Value | Description | ||
|---|---|---|---|---|
Connection Information | ||||
Cassandra Cluster Hosts | 192.168.234.136,192.168.234.136 | IP address(es) for the Cassandra cluster(s). These are the IP addresses or the host names configured during DSE setup to install the Cassandra cluster. | ||
Cassandra Cluster Port | 9042 | The port for the Cassandra cluster configured during DSE setup to install the Cassandra cluster. | ||
Cassandra User Name | n/a | Optional, unless you want to enable authentication on a cluster. In that case, this field is required.
| ||
Cassandra Password | n/a | Optional, unless you want to enable authentication on a cluster In that case, this field is required. (See above.) | ||
Cassandra Keyspace Name | thingworxnd | The location that ThingWorx data points to. Similar to a schema in a relational database.
| ||
Solr Cluster URL | http://localhost | If data tables are being used, provide IP or fully qualified host name including the domain or the IP configured during DSE setup to install the Cassandra cluster. | ||
Solr Cluster Port | 8983 | If data tables are being used, provide the port configured during DSE setup to install the Cassandra cluster. | ||
Cassandra Keyspace Settings | replication = {'class':'NetworkTopologyStrategy', 'Cassandra':1, 'Solr':1} | Dependent on your Cassandra cluster configuration created during DSE setup. Primarily defines the data centers used and the associated replication factors (refer to http://datastax.com/documentation/cql/3.1/cql/cql_reference/create_keyspace_r.html for details). If the administrators created the keyspace manually, then these settings should match the manually created keyspace settings. | ||
Cassandra Consistency Levels | {'Cluster' : { 'read' : 'ONE', 'write' : 'ONE' }} | Read and write consistency levels for the number of nodes.
| ||
CQL Query Result Limit | 5000 | Cassandra Query Language query result limit specifies the number of row returned when querying the data. This enhances the stability of ThingWorx by not allowing large results sets that would cause performance issues in the platform to be returned. | ||
Keep Connection Alive | true | Helps to keep the connections to the Cassandra cluster alive, especially across firewalls, where the inactive connections could be dropped.
| ||
Connection Timeout (Millis) | 30000 | Initial connection time-out in milliseconds. Depends on the network latency between ThingWorx and the Cassandra cluster. | ||
Compression Algorithm | none | When ThingWorx sends data to a cluster, there are three options: • Lz4 compression • Snappy compression • No compression If the network bandwidth between ThingWorx and the Cassandra cluster is low, then using a compression will increase the throughput.
| ||
Maximum Query Retries | 3 | The maximum number of retries enabled for queries. The default is three. | ||
Local Core Connections | 4 | Minimum number of connections that are able to read/ write data. | ||
Local Max Connections | 16 | Maximum number of connections that are able to read/write data | ||
Remote Core Connections | 2 | Minimum number of remote connections that are able to read/write data. | ||
Remote Max Connections | 16 | Maximum number of remote connections that are able to read/write data | ||
Enable Tracing | false | Logging. Can be enabled for debugging. | ||
Max Async Requests | 1000 | |||
Classic Stream Settings | ||||
Cache Initial Size | 10000 | The initial cache size. This is dependent on the number of sources.
| ||
Cache Maximum Size | 100000 | The max cache size. Controls memory usage. | ||
Cache Concurrency | 24 | The number of threads you can access at the same time. The minimum value should reflect the value set for Remote Max Connections. | ||
Classic Stream Defaults | ||||
Source Bucket Count | 1000 | Sources can be put into buckets. The number of sources equals the number of queries that need to be executed. For example, if you have 100,000 sources, this field determines how many buckets are used.
| ||
Time Bucket Size (Hours) | 24 | The time (in hours) to create buckets. Dependent on how the source bucket size is set up. For example, if the Time Bucket Size is set to 24, buckets will be created every 24 hours. The goal is to try not to exceed 2 million data points. So, depending on the data ingestion rate (R per second) per value stream or classic stream: Time Bucket Size = 2 mil / (R * 60 * 60)
| ||
Data Table Defaults | ||||
Data Table Bucket Count | 3 | A data table can be split into buckets. This allows a data table to be spread across DSE nodes. A value higher than the number of nodes in the cluster is recommended to allow data spread when the number of nodes increases depending on the load. The other factor to consider is the number of rows expected in the data table. Consider limiting to 200,000 rows per bucket. The setting here is the default. The bucket count can be specified per data table.
| ||
Value Stream Settings | ||||
Cache Initial Size | 10000 | The initial cache size. This is dependent on the number of sources multiplied by number of properties per source. | ||
Cache Maximum Size | 100000 | The maximum cache size. Controls memory usage. | ||
Cache Concurrency | 24 | The number of threads you can access at the same time. | ||
Value Stream Defaults | ||||
Source Bucket Count | 1000 | Sources can be put into buckets. The number of sources equals the number of queries that need to be executed. For example, if you have 100,000 sources, this field determines how many buckets are used.
| ||
Property Bucket Count | 1000 | The number of buckets depends on the number of properties per value stream and the query pattern. If there are queries spanning across properties, a smaller bucket size will yield the best performance. | ||
Time Bucket Size (Hours) | 24 | The size of the bucket(s). Dependent on how the source bucket size is set up. For example, if the Time Bucket Size is set to 24, buckets will be created every 24 hours.
| ||
6. If necessary, migrate entities and data.
7. Monitor and maintain your DSE implementation. Best practices for creating a successful maintenance plan are described here.